Build your own AlphaZero AI using Python and Keras

Teach a machine to learn Connect4 strategy through self-play and deep learning
In this article I’ll attempt to cover three things:
- Two reasons why AlphaZero is a massive step forward for Artificial Intelligence
- How you can build a replica of the AlphaZero methodology to play the game Connect4
- How you can adapt the code to plug in other games

First, a quick note about a new platform, The Network — a place where data scientists can find paid contract projects with businesses!
Click ‘Register’ to start building your profile.
AlphaGo → AlphaGo Zero → AlphaZero
In March 2016, Deepmind’s AlphaGo beat 18 times world champion Go player Lee Sedol 4–1 in a series watched by over 200 million people. A machine had learnt a super-human strategy for playing Go, a feat previously thought impossible, or at the very least, at least a decade away from being accomplished.

This in itself, was a remarkable achievement. However, on 18th October 2017, DeepMind took a giant leap further.
The paper ‘Mastering the Game of Go without Human Knowledge’ unveiled a new variant of the algorithm, AlphaGo Zero, that had defeated AlphaGo 100–0. Incredibly, it had done so by learning solely through self-play, starting ‘tabula rasa’ (blank state) and gradually finding strategies that would beat previous incarnations of itself. No longer was a database of human expert games required to build a super-human AI .

A mere 48 days later, on 5th December 2017, DeepMind released another paper ‘Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm’ showing how AlphaGo Zero could be adapted to beat the world-champion programs StockFish and Elmo at chess and shogi. The entire learning process, from being shown the games for the first time, to becoming the best computer program in the world, had taken under 24 hours.
With this, AlphaZero was born — the general algorithm for getting good at something, quickly, without any prior knowledge of human expert strategy.
There are two amazing things about this achievement:
1. AlphaZero requires zero human expertise as input
It cannot be overstated how important this is. This means that the underlying methodology of AlphaGo Zero can be applied to ANY game with perfect information (the game state is fully known to both players at all times) because no prior expertise is required beyond the rules of the game.
This is how it was possible for DeepMind to publish the chess and shogi papers only 48 days after the original AlphaGo Zero paper. Quite literally, all that needed to change was the input file that describes the mechanics of the game and to tweak the hyper-parameters relating to the neural network and Monte Carlo tree search.
2. The algorithm is ridiculously elegant
If AlphaZero used super-complex algorithms that only a handful of people in the world understood, it would still be an incredible achievement. What makes it extraordinary is that a lot of the ideas in the paper are actually far less complex than previous versions. At its heart, lies the following beautifully simple mantra for learning:
Mentally play through possible future scenarios, giving priority to promising paths, whilst also considering how others are most likely to react to your actions and continuing to explore the unknown.
After reaching a state that is unfamiliar, evaluate how favourable you believe the position to be and cascade the score back through previous positions in the mental pathway that led to this point.
After you’ve finished thinking about future possibilities, take the action that you’ve explored the most.
At the end of the game, go back and evaluate where you misjudged the value of the future positions and update your understanding accordingly.
Doesn’t that sound a lot like how you learn to play games? When you play a bad move, it’s either because you misjudged the future value of resulting positions, or you misjudged the likelihood that your opponent would play a certain move, so didn’t think to explore that possibility. These are exactly the two aspects of gameplay that AlphaZero is trained to learn.
How to build your own AlphaZero
Firstly, check out the AlphaGo Zero cheat sheet for a high level understanding of how AlphaGo Zero works. It’s worth having that to refer to as we walk through each part of the code. There’s also a great article here that explains how AlphaZero works in more detail.
The code
Clone this Git repository, which contains the code I’ll be referencing.
To start the learning process, run the top two panels in the run.ipynb Jupyter notebook. Once it’s built up enough game positions to fill its memory the neural network will begin training. Through additional self-play and training, it will gradually get better at predicting the game value and next moves from any position, resulting in better decision making and smarter overall play.
We’ll now have a look at the code in more detail, and show some results that demonstrate the AI getting stronger over time.
N.B — This is my own understanding of how AlphaZero works based on the information available in the papers referenced above. If any of the below is incorrect, apologies and I’ll endeavour to correct it!
Connect4
The game that our algorithm will learn to play is Connect4 (or Four In A Row). Not quite as complex as Go… but there are still 4,531,985,219,092 game positions in total.

The game rules are straightforward. Players take it in turns to enter a piece of their colour in the top of any available column. The first player to get four of their colour in a row — each vertically, horizontally or diagonally, wins. If the entire grid is filled without a four-in-a-row being created, the game is drawn.
Here’s a summary of the key files that make up the codebase:
game.py
This file contains the game rules for Connect4.
Each squares is allocated a number from 0 to 41, as follows:

The game.py file gives the logic behind moving from one game state to another, given a chosen action. For example, given the empty board and action 38, the takeAction method return a new game state, with the starting player’s piece at the bottom of the centre column.
You can replace the game.py file with any game file that conforms to the same API and the algorithm will in principal, learn strategy through self play, based on the rules you have given it.
run.ipynb
This contains the code that starts the learning process. It loads the game rules and then iterates through the main loop of the algorithm, which consist of three stages:
- Self-play
- Retraining the Neural Network
- Evaluating the Neural Network
There are two agents involved in this loop, the best_player and the current_player.
The best_player contains the best performing neural network and is used to generate the self play memories. The current_player then retrains its neural network on these memories and is then pitched against the best_player. If it wins, the neural network inside the best_player is switched for the neural network inside the current_player, and the loop starts again.
agent.py
This contains the Agent class (a player in the game). Each player is initialised with its own neural network and Monte Carlo Search Tree.
The simulate method runs the Monte Carlo Tree Search process. Specifically, the agent moves to a leaf node of the tree, evaluates the node with its neural network and then backfills the value of the node up through the tree.
The act method repeats the simulation multiple times to understand which move from the current position is most favourable. It then returns the chosen action to the game, to enact the move.
The replay method retrains the neural network, using memories from previous games.
model.py

This file contains the Residual_CNN class, which defines how to build an instance of the neural network.
It uses a condensed version of the neural network architecture in the AlphaGoZero paper — i.e. a convolutional layer, followed by many residual layers, then splitting into a value and policy head.
The depth and number of convolutional filters can be specified in the config file.
The Keras library is used to build the network, with a backend of Tensorflow.
To view individual convolutional filters and densely connected layers in the neural network, run the following inside the the run.ipynb notebook:
current_player.model.viewLayers()

MCTS.py
This contains the Node, Edge and MCTS classes, that constitute a Monte Carlo Search Tree.
The MCTS class contains the moveToLeaf and backFill methods previously mentioned, and instances of the Edge class store the statistics about each potential move.
config.py
This is where you set the key parameters that influence the algorithm.

Adjusting these variables will affect that running time, neural network accuracy and overall success of the algorithm. The above parameters produce a high quality Connect4 player, but take a long time to do so. To speed the algorithm up, try the following parameters instead.

funcs.py
Contains the playMatches and playMatchesBetweenVersions functions that play matches between two agents.
To play against your creation, run the following code (it’s also in the run.ipynb notebook)
from game import Game
from funcs import playMatchesBetweenVersions
import loggers as lg
env = Game()
playMatchesBetweenVersions(
env
, 1 # the run version number where the computer player is located
, -1 # the version number of the first player (-1 for human)
, 12 # the version number of the second player (-1 for human)
, 10 # how many games to play
, lg.logger_tourney # where to log the game to
, 0 # which player to go first - 0 for random
initialise.py
When you run the algorithm, all model and memory files are saved in the run folder, in the root directory.
To restart the algorithm from this checkpoint later, transfer the run folder to the run_archive folder, attaching a run number to the folder name. Then, enter the run number, model version number and memory version number into the initialise.py file, corresponding to the location of the relevant files in the run_archive folder. Running the algorithm as usual will then start from this checkpoint.
memory.py
An instance of the Memory class stores the memories of previous games, that the algorithm uses to retrain the neural network of the current_player.
loss.py
This file contains a custom loss function, that masks predictions from illegal moves before passing to the cross entropy loss function.
settings.py
The locations of the run and run_archive folders.
loggers.py
Log files are saved to the log folder inside the run folder.
To turn on logging, set the values of the logger_disabled variables to False inside this file.
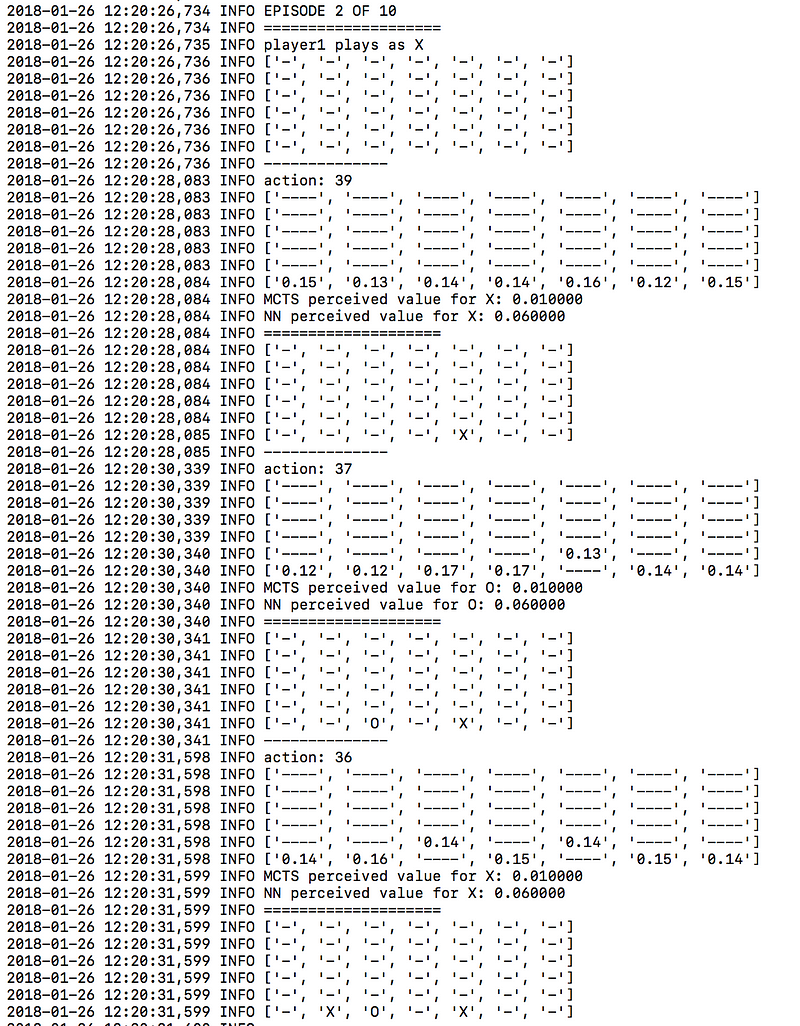
Viewing the log files will help you to understand how the algorithm works and see inside its ‘mind’. For example, here is a sample from the logger.mcts file.

Equally from the logger.tourney file, you can see the probabilities attached to each move, during the evaluation phase:

Results
Training over a couple of days produces the following chart of loss against mini-batch iteration number:

The top line is the error in the policy head (the cross entropy of the MCTS move probabilities, against the output from the neural network). The bottom line is the error in the value head (the mean squared error between the actual game value and the neural network predict of the value). The middle line is an average of the two.
Clearly, the neural network is getting better at predicting the value of each game state and the likely next moves. To show how this results in stronger and stronger play, I ran a league between 17 players, ranging from the 1st iteration of the neural network, up to the 49th. Each pairing played twice, with both players having a chance to play first.
Here are the final standings:
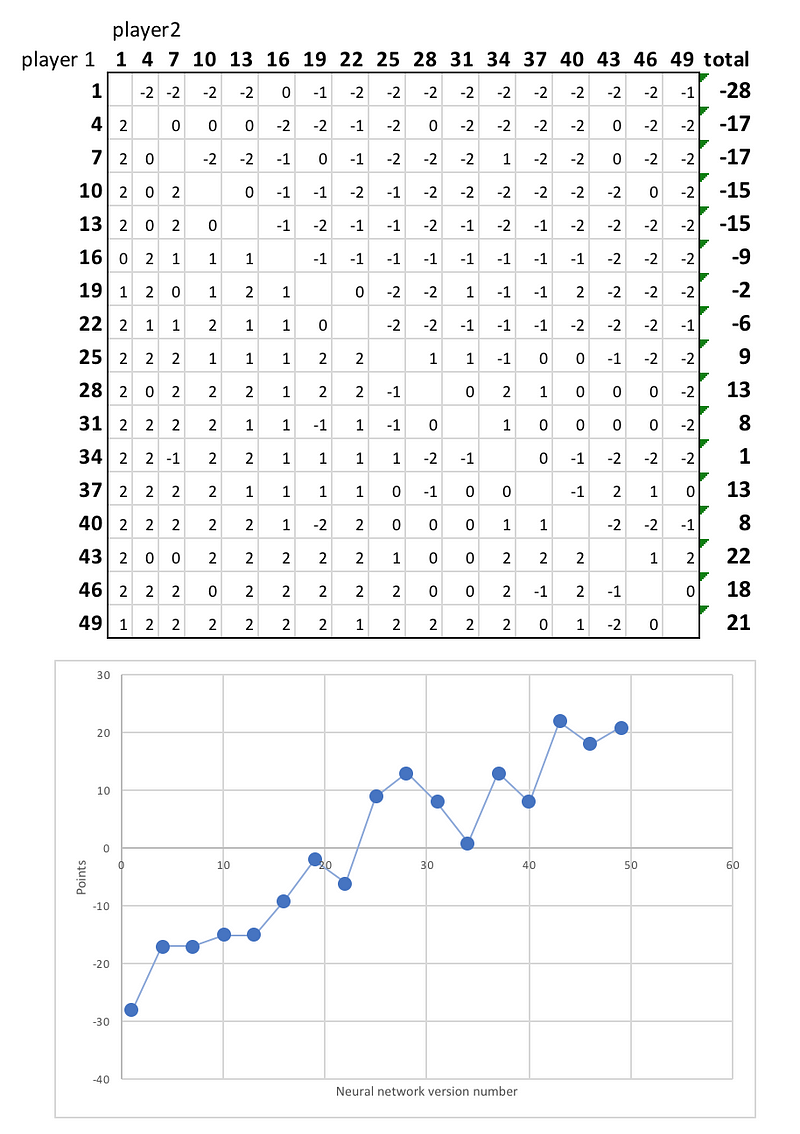
Clearly, the later versions of the neural network are superior to the earlier versions, winning most of their games. It also appears that the learning hasn’t yet saturated — with further training time, the players would continue to get stronger, learning more and more intricate strategies.
As an example, one clear strategy that the neural network has favoured over time is grabbing the centre column early. Observe the difference between the first version of the algorithm and say, the 30th version:
1st neural network version
30th neural network version
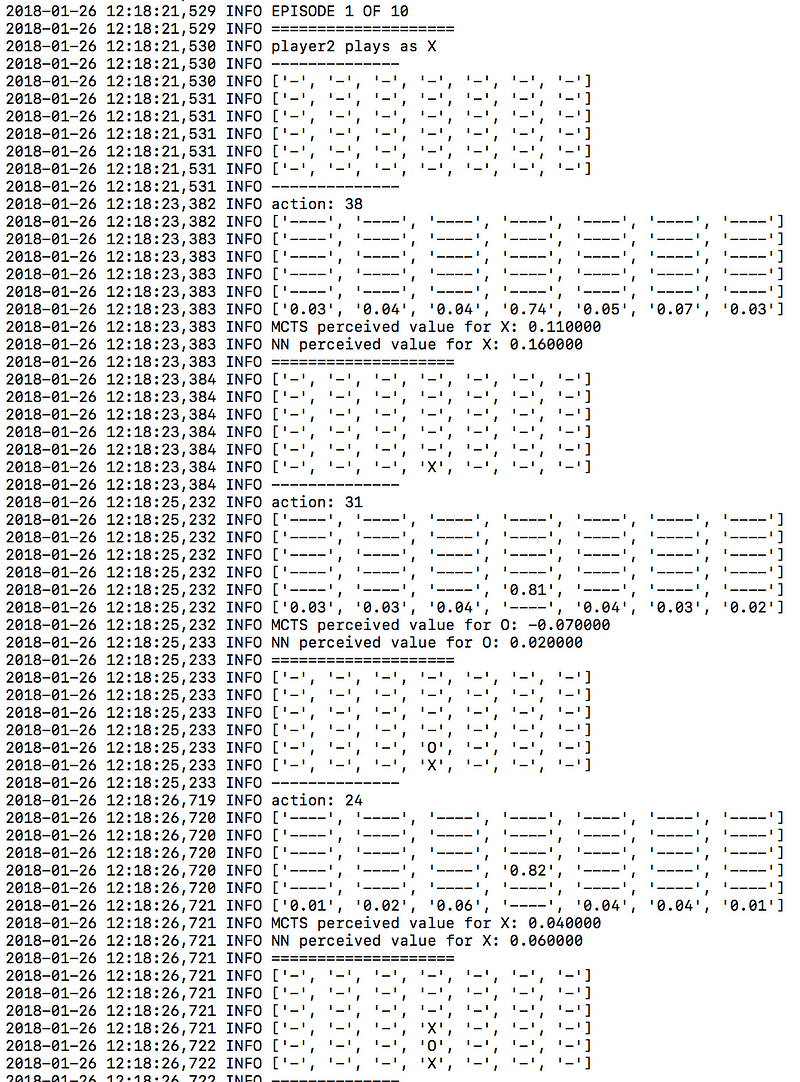
This is a good strategy as many lines require the centre column — claiming this early ensures your opponent cannot take advantage of this. This has been learnt by the neural network, without any human input.
Learning a different game
There is a game.py file for a game called ‘Metasquares’ in the games folder. This involves placing X and O markers in a grid to try to form squares of different sizes. Larger squares score more points than smaller squares and the player with the most points when the grid is full wins.
If you switch the Connect4 game.py file for the Metasquares game.py file, the same algorithm will learn how to play Metasquares instead.
Summary
Hopefully you find this article useful — let me know in the comments below if you find any typos or have questions about anything in the codebase or article and I’ll get back to you as soon as possible.

If you would like to learn more about how our company, Applied Data Science develops innovative data science solutions for businesses, feel free to get in touch through our website or directly through LinkedIn.
Applied Data Science is a London based consultancy that implements end-to-end data science solutions for businesses, delivering measurable value. If you’re looking to do more with your data, let’s talk.
30s ad
☞ Artificial Intelligence A-Z™: Learn How To Build An AI
☞ Artificial Intelligence 2018: Build the Most Powerful AI
☞ ChatBots: Messenger ChatBot with API.AI and Node.JS
☞ ChatBots: Messenger ChatBot with API.AI and Node.JS
☞ Intelligent Mobile Apps with Ionic and API.AI (DialogFlow)
Suggest:
☞ Python Machine Learning Tutorial (Data Science)
☞ Python Tutorial for Data Science
☞ Machine Learning Zero to Hero - Learn Machine Learning from scratch
☞ Complete Python Tutorial for Beginners (2019)