Top 5 Machine Learning Projects for Beginners

, and second of all, study the data set in order to find out which machine learning algorithm class or type will fit best on the set of data.
Here are some tips from experts on how to get started:
- Find a modestly sized data set which is relatively easy to analyze. Good places to search are the UCI ML Repository and Kaggle.
- Experiment with the data set. To get a good “feeling” with the data set, you can run several top machine learning algorithms on the data to see how it behaves and what performance each algorithm achieves.
- Pick the algorithm with the best performance and tune it accordingly.
Ok, now we are packed with a couple of general tips to get started on your ML project, let’s take a look at 10 interesting examples that will teach you how to use ML algorithms, tune them, but also how to analyze the given data.
1. Supervised Machine Learning w/ Iris Flowers Classification
The Iris Flowers dataset is seen as the “Hello World” of ML as it’s the classic example of classification. This dataset offers a great introduction as it requires you to learn how to explore data and how to load it. The benefit of this dataset is that is small to load into your memory (150 rows) and it has only four properties: Petal length, Petal width, Sepal length, and Sepal width.

The project involves the identification of four different species of Iris flowers using the four known properties. The dataset allows you to use a supervised learning algorithm as the data is labeled whereas unsupervised means that we are looking for hidden structures in the data as the data is unlabeled.
Classification Type? We are using Multiclass Classification here. This means that we should be able to predict accurately to which class a data point belongs.
Goal: Classify flowers among three species based on the properties of the flower: dimensions of petals and sepals.
Download: Iris Flowers Dataset
Full guide: To solving the problem can be found here.
2. Transactions Predictions w/ GNY
Machine Learning has been a trending topic for years now but many popular services are inaccessible for most developers primarily because of cost. A group called GNY is solving that with a decentralize their powerful machine learning platform that will be free to download and install. The machine learning platform is actually embedded within a blockchain so a user’s data is protected from potential hacks.
The team has released a demo that shows how this platform can predict groups of retail transactions through their powerful neural net, and a fully downloadable and customizable version of the platform is launching this Summer. GNY will have a library of selectable machine learning code sets that can be selected depending on the requirements of each individual and can be applied to their sidechain (as GNY will use Lisk’s sidechain technology).
Why is this so important? Almost all businesses are looking for an affordable way to unlock hidden value in their data, but not if it exposes them to security risks. The inherent structure of a blockchain helps to control data consistency and allow you to remain in control over your data
Performance increases as the validation can already be started for the subsequent block while the previous block is still active. Validation includes checking if the user has sufficient balance. Only for the wrongly predicted transactions, this work needs to be redone.

This demo is a fun starter project for people who want to predict simple numbers and the full platform launching this Summer should provide developers with much more power and customization. A good data set can be found at MLWave for predicting repeat buyers using purchase history.
Goal: Predict future transactions based on spending history.
3. Sentiment Analysis w/ Twitter
One interesting application of machine learning is sentiment analysis. Sentiment analysis has seen a major breakthrough with the rise of cryptocurrencies. Many have tried to build trading bots that incorporate sentiment analysis to make better trading decisions.

There are many other platforms that can be used for sentiment analysis like Reddit, Facebook, or LinkedIn as they all offer easy-to-use APIs for retrieving data. However, due to the consistent format of the data on the Twitter platform, this is the preferred data for machine learning. It is also much easier to pre-process as the tweets mainly consist of text, URLs, and hashtags.
The Twitter API knows many API libraries that can be used for integrating into your project. The wrapper for Python can be installed via pip with !pip install python-twitter . However, watch out when using the API as excessive usage can get you blacklisted. Therefore, Twitter provides guidelines on how to avoid being rate limited. If you require real-time data, the Twitter streaming API can save you.
A couple of fun examples to analyze:
- Sentiment surrounding a newly released movie and compare it with reviews on IMDB and other rating websites.
- Sentiment surrounding a particular election or any other trending political topic.
- Predict the future direction of the price of a top 50 cryptocurrency based on the sentiments of its tweets.
Goal: A sentiment analyzer learns the various sentiments behind a piece of content. This task helps you think about designing various models to label a tweet as positive or negative. In a later phase, we can label tweets in a more nuanced way like ‘neutral’, ‘angry’, ‘optimistic’, …
Github Overview: of all Twitter-related data sets.
4. Recommender Systems w/ Movielens
Recommender systems are one of the most successful and widespread applications of machine learning technologies in business. You find recommender systems everywhere in your daily life. For example, when watching Youtube videos, the Youtube algorithm will propose you recommended videos based on your watching habits but also key insights they gained on watching patterns from running ML algorithms on the watching behavior of people all across the world.
We can find two types of algorithms for recommender systems:
- Content-based: As the label says, it looks for similarity in content.
- Collaborative filtering methods: This method looks for similarity in interactions. An example of an interaction can be looking at the ratings of a user and comparing them with others to find similar behavior/likings. The below picture illustrates this.

Currently, Movielens provides one of the most popular data sets for movie ratings which is an ideal dataset for beginners to experiment with.
Goal: Predict which movies users will like based on their ratings.
Website: Grouplens.org
Tutorial: Towardsdatascience provides a tutorial for building a simple Recommender System in Python.
5. Stock Price Predictions w/ Quandl
Stock prices predictor is a system that learns about the performance of a company and predicts future stock prices. The tricky thing with stock price predictions is that many types and sources of data can be used:
- Volatility indices
- Historical prices
- Global macroeconomic indicators
- Fundamental analysis
- Technical analysis using indicators
The benefit of analyzing the stock market is that it has shorter feedback cycles which makes it easier to validate your predictions. If you don’t know market cycles, I suggest to read up about this topic to understand how a typical cycle looks like.
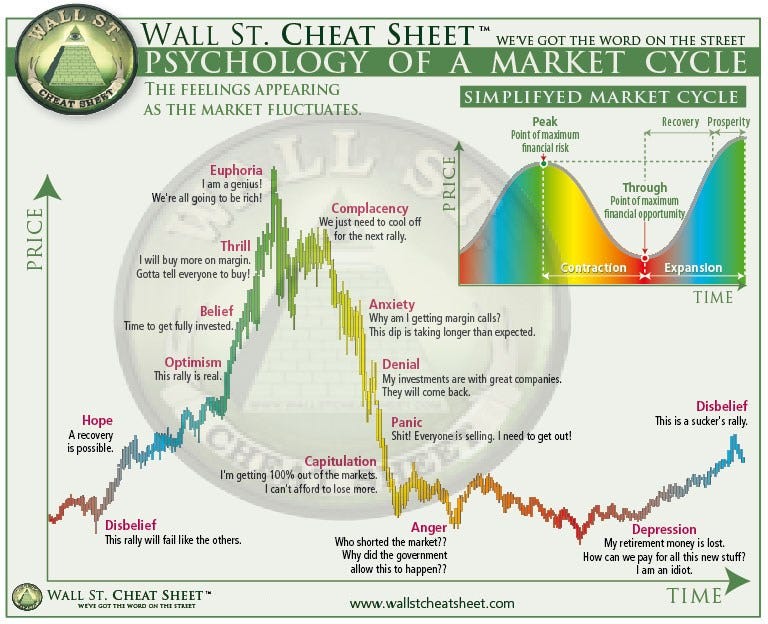
To start off easy, you can pick up a simple machine learning example where we predict the 6-month price movement based on fundamental indicators from an organization his quarterly report.
Goal: Predict future price using fundamental and technical indicators.
Download: Stock market datasets from Quandl.com or Quantoplan.com.
✅Further reading:
☞ Machine Learning Guide: Learn Machine Learning Algorithms
☞ Hands-On Machine Learning: Learn TensorFlow, Python, & Java!
☞ Learn Azure Machine Learning from scratch
☞ Master Machine Learning , Deep Learning with Python
☞ Artificial Intelligence - TensorFlow Machine Learning
Suggest:
☞ Machine Learning Zero to Hero - Learn Machine Learning from scratch
☞ Introduction to Machine Learning with TensorFlow.js
☞ Platform for Complete Machine Learning Lifecycle
☞ Python Machine Learning Tutorial (Data Science)
☞ Deep Q Learning is Simple with Keras | Tutorial
☞ Deep Learning and Modern Natural Language Processing (NLP)