Reactive programming in Node.js with RxJS

The benefits are clear: an efficient use of resources. But the benefits come at a cost: a non-trivial increase in complexity.
Over time, vendors and the open source community have tried to find ways to reduce such complexity without compromising the benefits.
Asynchronous processing started with ‘callbacks’, then came Promise and Future, async and await. Recently another kid has come to town — ReactiveX with its various language implementations — bringing the developers a new powerful tool, the Observable.
In this article, we want to show how Observables implemented by RxJs (the JavaScript embodiment of ReactiveX) can simplify code to be executed with Node.js, the popular server-side JavaScript non-blocking environment.
A simple use case — Read, Transform, Write, and Log
To make our reasoning concrete, let’s start from a simple use case. Let’s assume we need to read the files contained in **Source Dir**,transform their content and write the new transformed files in a **Target Dir**, while keeping a log of the files we have created.
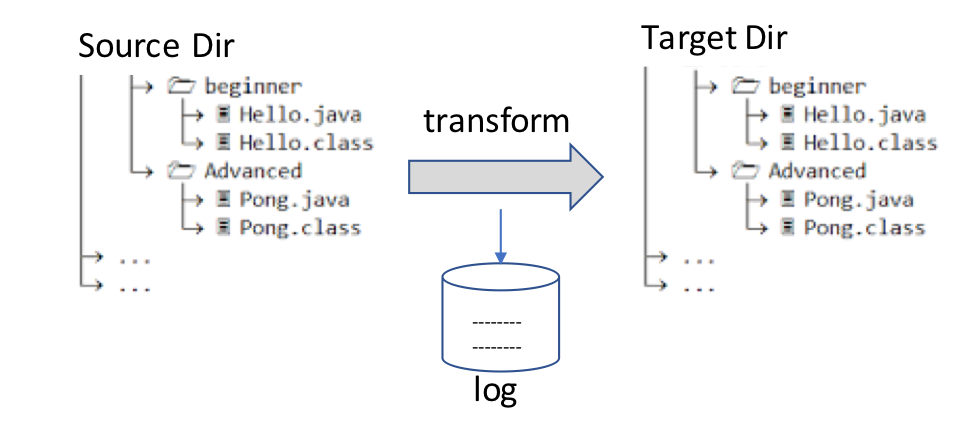
Synchronous implementation
The synchronous implementation of this use case is pretty straightforward. In a sort of pseudo code representation, we could think of something like:
read the names of the files of Source Dir
for each file name
read the file
transform the content
write the new file in Target Dir
log the name of the new file
end for
console.log('I am done')
There is nothing special to comment here. We can just say that we are sure of the sequence of execution of each line and that we are sure that things will happen as described by the following flow of events. Each circle corresponds to the completion of an I/O operation.

What happens in an asynchronous non-blocking environment like Node.js
Node.js is an asynchronous non-blocking execution environment for JavaScript. Non-blocking means that Node.js does not wait for I/O or Network operations to complete before moving to the execution of the next line of code.
Processing one file
Reading and writing files are I/O operations where Node.js shows its non-blocking nature. If a Node.js program asks for a file to read, it has to provide a function to be executed when the file content is available (the so called callback) and then immediately move on to the next operation to execute.
Let’s consider the case of just one file. Reading, transforming, writing one file and updating the log in Node.js looks something like this:
import * as fs from 'fs'; // Node module to access file system
const fileName = 'one-file.txt';
fs.readFile(fileName, callback(err, data) => {
const newContent = transform(data);
const newFileName = newFileName(fileName); // calculate new name
fs.writeFile(newFileName, newContent, err => {
if(err) {// handle error};
fs.appendFile('log.txt', newFileName + ' written', err = {
if (err) {// handle error}
});
});
})
The syntax may look a bit convoluted with 2 levels of indentation, but if we think of what happens in terms of events we can still precisely foresee the sequence:

The paradise of Promise
This is the use case where JavaScript Promise shines. Using Promise we can make the code look again sequential, without interfering with the asynchronous nature of Node.js.
Assuming we can access functions that perform read and write operations on file and return a Promise, then our code would look like:
const fileName = 'my-file.txt';
readFilePromise(fileName)
.then(data => {
const newContent = transform(data);
const newFileName = newFileName(fileName); // build the new name
return writeFilePromise(newFileName, newContent)
})
.then(newFileName => appendFile('log.txt', newFileName))
.then(newFileName => console.log(newFileName + ' written'))
.catch(err => // handle error)
There are several ways to transform Node.js functions in Promise based functions. This is one example:
function readFilePromise(fileName: string): Promise<Buffer>{
return new Promise(function(resolve, reject) {
fs.readFile(fileName, function(err, data: Buffer) {
if(err !== null) return reject(err);
resolve(data);
});
});
}
Processing many files
If we return to the original use case, where we have to transform all the files contained in a Directory, the complexity increases and Promises start showing some limits.
Let’s look at the events the Node.js implementation needs to manage:

Each circle represents the completion of one I/O operation, either read or write. Every line represents the processing of one specific file, or a chain of Promises.
Given the non-blocking nature of Node.js, there is no certainty on the sequence in time of such events. It is possible that we will finish writing **File2**before we finish reading **File3**.
The parallel processing of each file makes the use of Promises more complex (at the end of this article, a Promise based implementation is provided). This is the scenario where ReactiveX — RxJs in particular — and Observable shine and allow you to build elegant solutions.
What are Observables and what can you do with them?
There are many places where formal definitions of Observables are detailed, starting from the official site of ReactiveX.
Here I just want to remind you of a couple of properties that have always gotten my attention:
- Observable models a stream of events
- Observable is the “push” brother of Iterable, which is “pull”
As the “push” brother of Iterable, Observable offers developers many of the cool features provided by Iterables such as:
- Transform “streams of events” or Observables, via operators such as
map,filterandskip - Apply functional programming style
One additional very important thing that Observable offers is subscription. Via subscription, the code can apply “side effects” to events and perform specific actions when specific events happen, such as when errors occur or the stream of events completes.

As you can see, the Observable interface gives developers the possibility to provide three different functions which define what to do respectively when: an event is emitted with its data, an error occurs, or the stream of events completes.
I guess all of the above may sound very theoretical to those who have not yet played with Observable, but hopefully the next part of the discussion, which is focused on our use case, will make these concepts more concrete.
Implementation of the Read, Transform, Write, and Log use case via Observable
Our use case starts with reading the list of files contained in **Source Dir**. So, let’s start from there.
Read all the file names contained in a Directory
Let’s assume we have access to a function which receives as input the name of a directory and returns an Observable which emits the list of file names of the directory once the directory tree structure has been read.
readDirObservable(dirName: string) : Observable<Array<string>>
We can subscribe to this Observable and when all file names have been read, start doing something with them:

Read a list of files
Let’s assume now that we can access a function which receives as input a list of file names and emits each time a file has been read (it emits the content of the file Buffer, and its name string).
readFilesObservable(fileList: Array<string>)
: Observable<{content: Buffer, fileName: string}>
We can subscribe to such Observable and start doing something with the content of the files.
Combining Observables — switchMap operator
We have now two Observables, one that emits a list of file names when the directory has been read and one that emits every time a file is read.
We need to combine them to implement the first step of our use case, which is: when readDirObservable emits, we need to switch to readFilesObservable .

The trick here is performed by the switchMap operator. The code looks like:
readDirObservable(dirName)
.switchMap(fileList => readFilesObservable(fileList))
.subscribe(
data => console.log(data.fileName + ‘ read’), // do stuff with the data received
err => { // manage error },
() => console.log(‘All files read’)
)
We must mention that the switchMap operator is more powerful than this. Its full power though can not be appreciated in this simple use case, and its full description is outside the scope of this post. If you are interested, this is an excellent article that describes in detail switchMap.
Observable generating a stream of Observables
We have now a stream of events representing the completion of a read operation. After the read we need to do a transformation of the content that, for sake of simplicity, we assume to be synchronous, and then we need to save the transformed content in a new file.
But writing a new file is again an I/O operation, or a non-blocking operation. So every ‘file-read-completion’ event starts a new path of elaboration that receives as input the content and the name of the source file, and emits when the new file is written in the Target Dir (the event emitted carries the name of the file written).
Again, we assume that we’re able to access a function that emits as soon as the write operation is completed, and the data emitted is the name of the file written.
writeFileObservable(fileName: string, content: Buffer) : Observable<string>
In this case, we have different “write-file” Observables, returned by the writeFileObservable function, which emits independently. It would be nice to merge them into a new Observable which emits any time each of these “write-file” Observables emit.
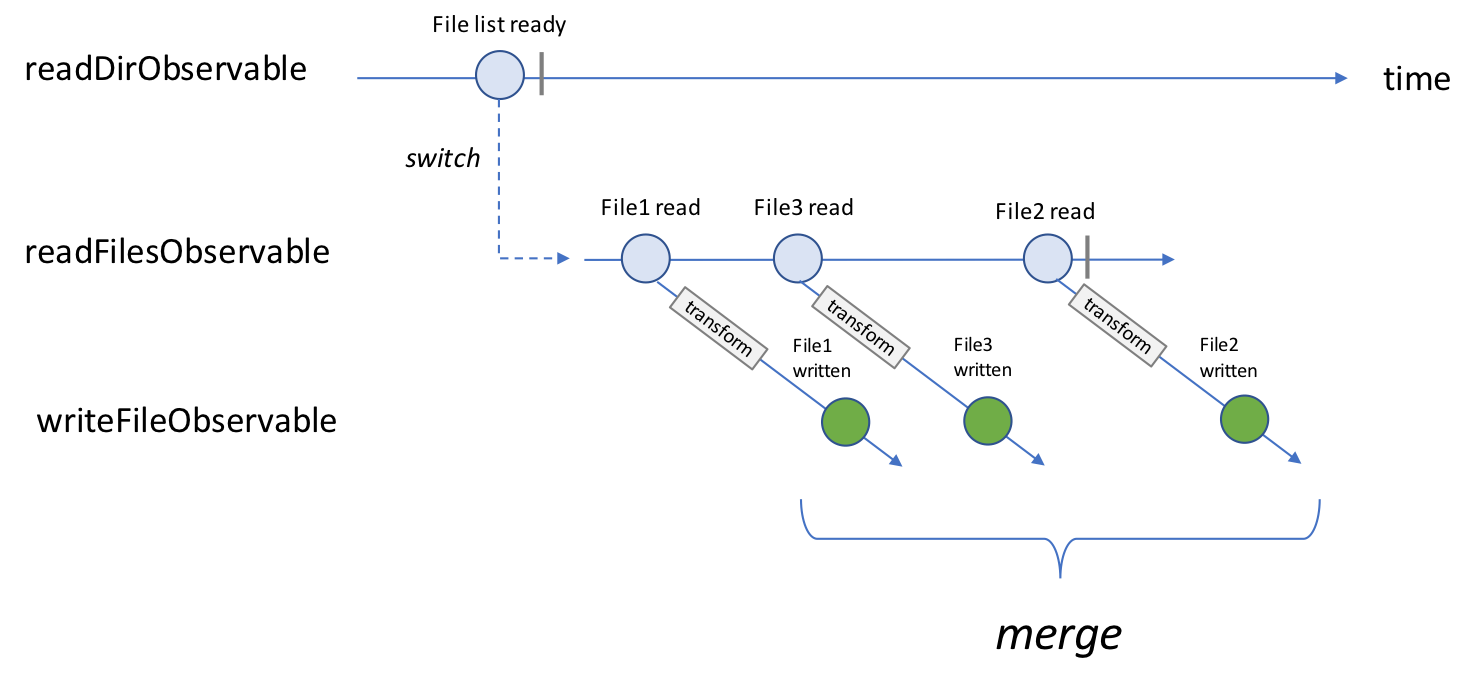
With ReactiveX (or RxJs in JavaScript) we can reach this result using the mergeMap operator (also known as a flatMap). This is what the code looks like:
readDirObservable(dir)
.switchMap(fileList => readFilesObservable(fileList))
.map(data => transform(data.fileName, data.content))
.mergeMap(data => writeFileObservable(data.fileName, data.content))
.subscribe(
file => console.log(data.fileName + ‘ written’),
err => { // manage error },
() => console.log(‘All files written’)
)
The mergeMap operator has created a new Observable, the writeFileObservable as illustrated in the following diagram:

So what?
Applying the same approach, if we just imagine that we have a new function of writeLogObservable, that writes a line on the log as soon as the file is written and emits the file name as soon as the log is updated, the final code for our use case would look like:
readDirObservable(dir)
.switchMap(fileList => readFilesObservable(fileList))
.map(data => transform(data.fileName, data.content))
.mergeMap(data => writeFileObservable(data.fileName, data.content))
.mergeMap(fileName => writeLogObservable(fileName))
.subscribe(
file => console.log(fileName + ‘ logged’),
err => { // manage error },
() => console.log(‘All files have been transformed’)
)
We do not have indentations introduced by the callbacks.
Time flows along the vertical axis only, so we can read the code line by line and reason about what is happening line after line.
We have adopted a functional style.
In other words, we have seen the benefits of Observable in action.
Create Observable from functions with callbacks
I hope you now think that this looks pretty cool. But even in this case you may have one question. All the functions that make this code cool just do not exist. There is no readFilesObservable or writeFileObservable in standard Node.js libraries. How can we create them?
bindCallback and bindNodeCallback
A couple of functions provided by Observable, namely bindCallback(and bindNodeCallback) come to our rescue.
The core idea behind them is to provide a mechanism to transform a function f which accepts a callback cB(cBInput) as input parameter into a function which returns an Observable obsBound which emits cBInput.In other words, it transforms the invocation of the cBin the emission of cBInput.
The subscriber of obsBound can define the function which will process cBInput(which plays the same role as cB(cBInput)). The convention applied is that the callback function cB(cBInput) must be the last argument off.
It is probably easier to understand the mechanism looking at the following diagram:

The starting point, the function **f(x, cb)** is the same in the two cases. The result (what is printed on the console) is the same in the two cases.
What is different is how the result is obtained. In the first case the result is determined by the callback function passed as input. In the second case it is determined by the function defined by the subscriber.
Another way of considering how bindCallback works is to look at the transformation it performs, as illustrated in the diagram below.

The first argument of f becomes the value passed to the new function fBound. The arguments used as parameters of the callback cb become the values emitted by the new Observable returned by fBound.
bindNodeCallback is a variation of bindCallback based on the convention that the callback function has an error parameter as the first parameter, along with the Node.js convention fs.readFile(err, cb).
Create Observables from non-callback functions
bindNodeCallback has been designed to work with functions which expect a callback as the last argument of their input, but we can make it work also with other functions.
Let’s consider the standard Node.js function readLine. This is a function used to read files line by line. The following example shows as it works:

Each line read is pushed into the lines array. When the file is completely read, the function processLinesCb is called.
Imagine now that we define a new function,_readLines, which wraps the logic defined above as shown by the following snippet:

Once all lines are read, they are processed by the function processLinesCb, which is the last input parameter of _readLines. _readLines is therefore a function that can be treated by bindCallback. Through this trick we can transform the Node.js function fs.readLine into an Observable using the usual bindCallback function as follows:

Conclusion
Asynchronous non-blocking processing is complex by nature. Our minds are used to think sequentially — this is true at least for those of us who started coding few years ago. We often find it challenging to reason about what is really happening in these environments. The callback-hell is just around the corner.
Promises and Futures have simplified some of the most frequent cases such as ‘one time’ asynchronous events, the ‘request now — respond later’ scenario typical of HTTP requests.
If we move from ‘one time’ events to ‘event streams’ Promises start showing some limitations. In such cases we may find ReactiveX and Observables a very powerful tool.
As promised: the Promise-based implementation of our use case
This is an implementation of the same use case based on Promises:
const promises = new Array<Promise>();
readDirPromise(dir)
.then(fileList => {
for (const file of fileList) {promises.push(
readFilePromise(file)
.then(file_content => transform(file_content))
.then(file => writeLogPromise(file))
);
}
return promises;
}
.then(promises => Promise.all(promises))
.then(() => console.log(‘I am done’))
.catch(err => { // manage error })
30s ad
☞ Node.js Unit Testing In-Depth
☞ Mastering REST APIs in Node.js: Zero To Hero
☞ Build a Real Time web app in node.js , Angular.js, mongoDB
☞ Master the MEAN Stack - Learn By Example
☞ ChatBots: Messenger ChatBot with API.AI and Node.JS
Suggest:
☞ JavaScript Programming Tutorial Full Course for Beginners
☞ React + TypeScript : Why and How
☞ Learn JavaScript - Become a Zero to Hero
☞ Javascript Project Tutorial: Budget App
☞ E-Commerce JavaScript Tutorial - Shopping Cart from Scratch