Instacart Anytime: A Data Science Paradigm

ave you ever ordered your groceries online? Partnering with hundreds of retailers, Instacart enables more than 50% of American households to order groceries online from their favorite stores. If you haven’t tried it yet, read The Instacart Experience to learn how Instacart works.
When customers shop for groceries on Instacart, they can select a delivery window to receive their groceries. Ideally customers are able to choose any delivery window (shown on the left screenshot above); however, sometimes there is more demand than shoppers can handle. For busy windows, we would have to either close them completely or increase their delivery fees to shift demand to other windows (illustrated on the right screenshot above).
This blog post introduces Instacart’s Shopper Staffing team, and our data science approach to achieving a desirable balance between maximizing availability of delivery times to customers and minimizing shopper idleness.
Let’s start with our mission statement and system overview, then delve into the subsystems (marketplace forecasting, supply planning, real-time capacity), and wrap up with our team snapshot.
Team Mission
The mission of the shopper staffing team is to match shopper supply to customer demand. We want customers to be able to choose their desired delivery windows without paying additional fees; meanwhile, we don’t want to schedule too many shoppers, which would result in redundant idleness. Essentially, we want to achieve a supply-demand balance that maximizes the aggregate benefits for both customers and shoppers.
Our team mission is quantified using these metrics:
- Availability − % of customer visits with available delivery windows
- Idleness − % of time when shoppers are not actively working
- Unmet Demand (i.e., Lost Deliveries from Instacart’s perspective) − potential orders that we may fail to accept due to lack of shoppers during certain time windows
System Overview
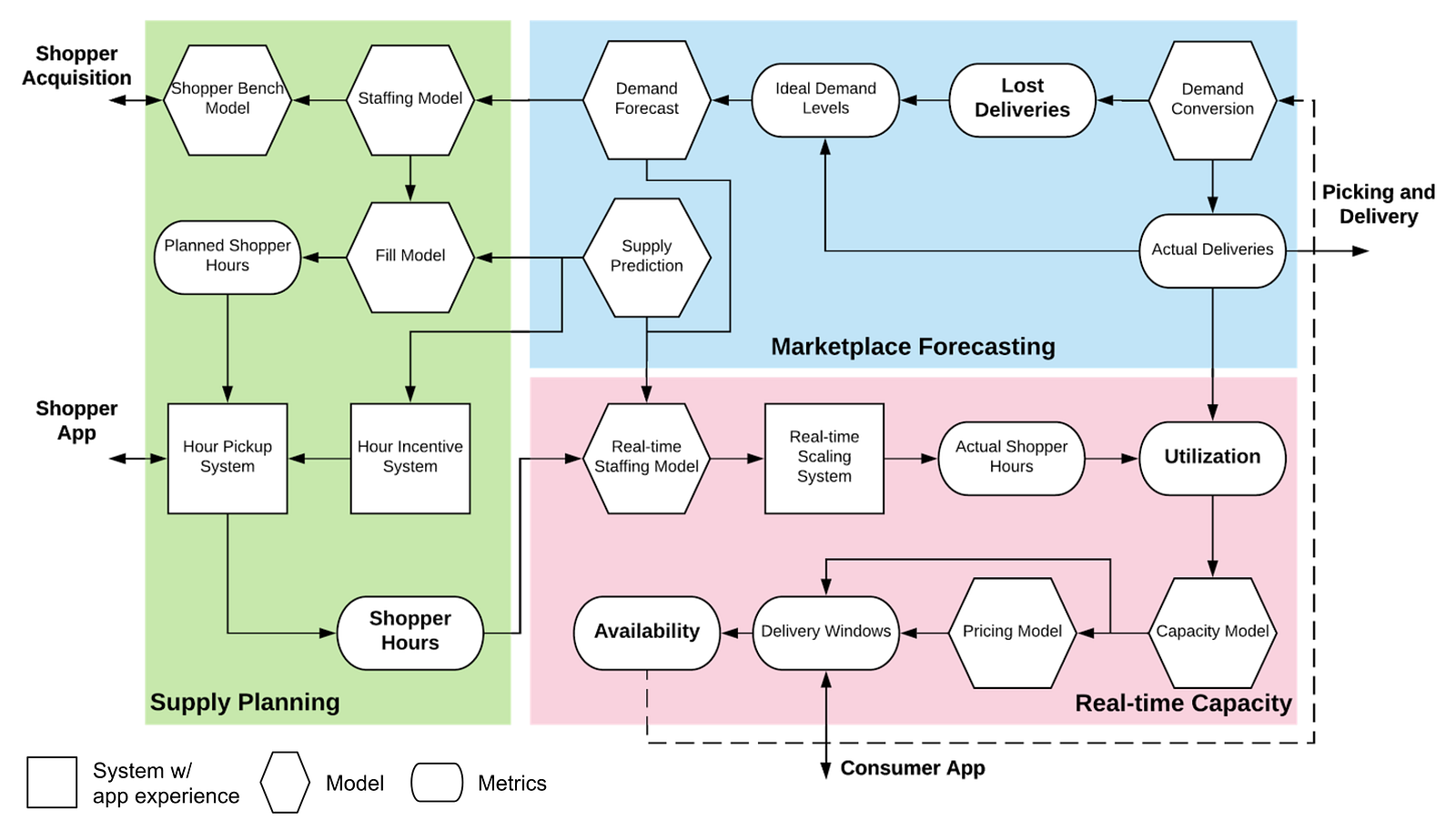
As depicted above, the staffing system consists of these subsystems:
- Marketplace Forecasting topredict demand and supply
- Supply Planning toestimate the total number of shoppers needed to fulfill the predicted long-term demand and to plan shopper hours to fulfill the predicted short-term demand
- Real-time Capacity to adjust shopper hours in real time, to estimate the capacities of delivery windows, and to optimize delivery prices to maximize demand conversion
Now let’s take a deep dive to these subsystems and scope out the data science problems inherent in these components.
Marketplace Forecasting

The goal of Marketplace Forecasting is to provide accurate demand and supply predictions for downstream decision-making systems. It includes the following data science problems:
- Demand Conversion: Every customer who visits Instacart may not place an order. Their order probability is dependent on a number of factors, such as what type of user they are, what delivery options were available to them, which city they are from, etc. The demand conversion model relates the order probability to these features.
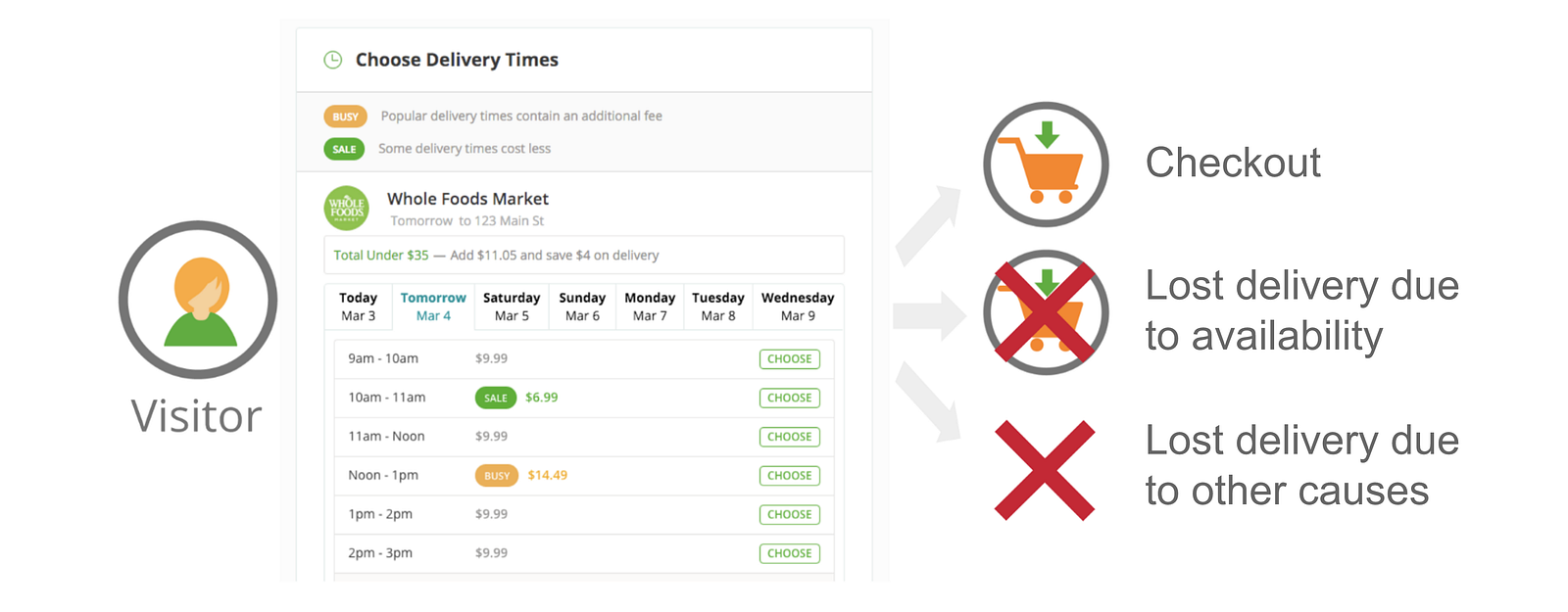
- Unmet Demand (i.e., Lost Deliveries) Estimation: As depicted above, if customers cannot find their favorite delivery windows at checkout, they may abandon their order. Such unmet demands hurt customer experience, and we call those lost deliveries. We want to estimate lost deliveries due to unavailable and busy delivery windows. For this purpose, we use causal inference or Bayesian networks to estimate the impact of specific features on demand conversion.
- Demand Forecasting: We combine actual and lost deliveries to estimate ideal demand levels, which serve as the input to demand forecasting. Weuse conventional time-series models to forecast seasonality of grocery sales on Instacart. In addition, we project demand several weeks out at the city level for recommending shopper acquisition, in parallel we also forecast hourly demand to plan supply at the store level. Different spatiotemporal use cases require us to handle different data sparsities when building demand forecasting models.
- Supply Prediction: Since Instacart shoppers work on their own schedules, we use machine learning models to predict the likelihood of claim and cancelation of any particular hours. Such predictions provide critical information to Supply Planning, so that we can fill shopper hours as accurately as we need in order to fulfill customer demand.
Supply Planning
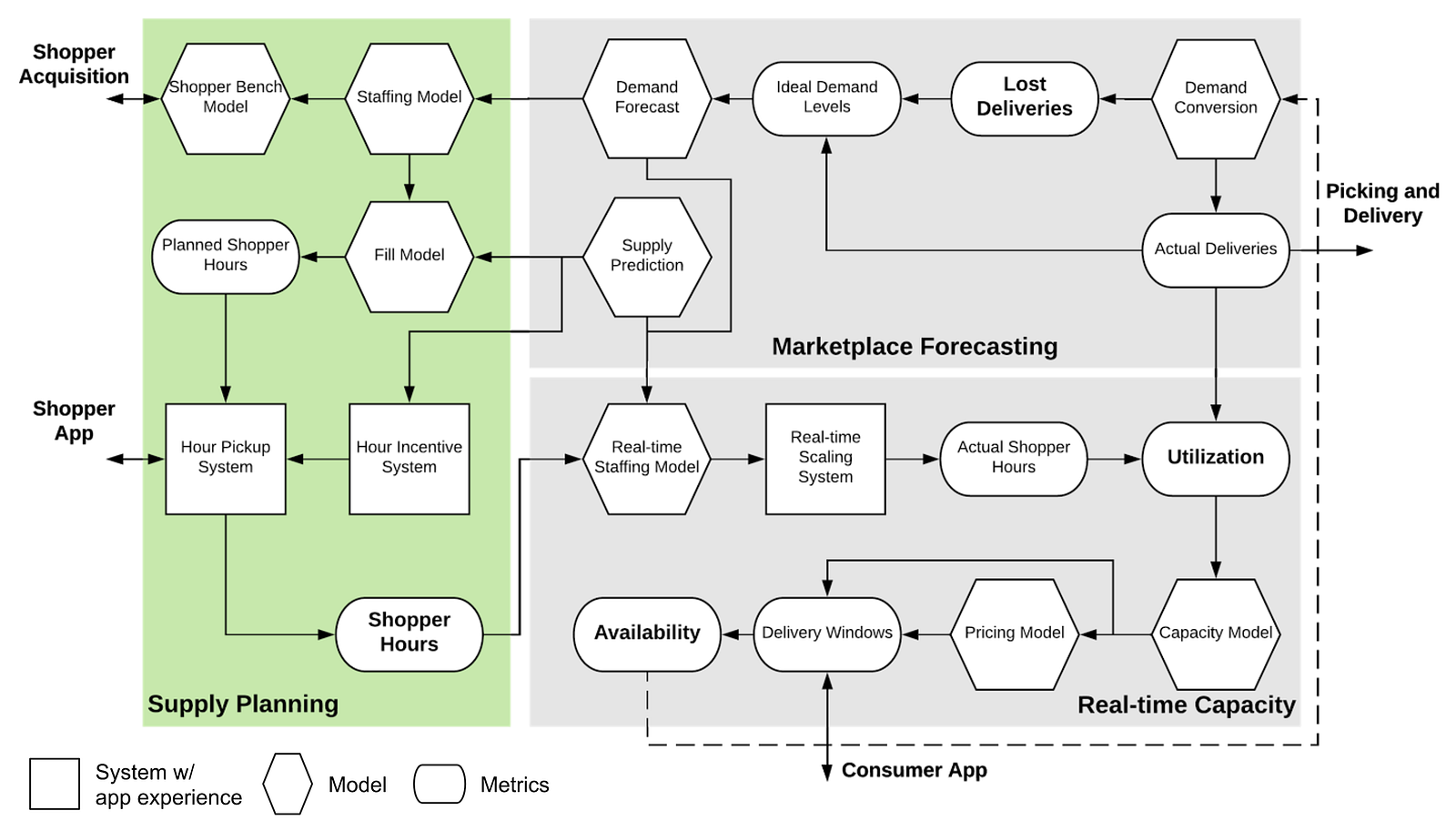
The goal of Supply Planning is to generate shopper hours as accurately as we need in order to fulfill customer demand. It includes the following data science problems:
- Staffing Model: This modelestimates how many shopper hours we need in order to fulfill the predicted demand. Our estimation considers not only demand levels and shopper efficiency, but also demand origins and destinations and the efficiency of our logistics system. Read No Order Left Behind; No Shopper Left Idle by Jagannath Putrevu to learn more about our Monte Carlo method to derive staffing levels from demand forecasts.
- Shopper Bench Model: Once we submit long-term demand projections to the staffing model, it predicts the total shopper hours we need for the upcoming weeks. We then use statistical modeling and microeconomic theory to derive the optimal number of shoppers needed for this period of time, which is used to acquire shoppers cost-effectively.
- Fill Model: As shoppers work on their own schedules, they can sign up or cancel their hours at any time. With supply predictions the fill model computes the right number of open hours at any time before the hours start, in order to maximize the likelihood of filling shopper hours as accurately as we need to fulfill customer demand.
- Hour Incentive Model: Different hours have different acceptance probabilities. With supply predictions the hour incentive model classifies hours into different categories based on acceptance probabilities and applies incentives accordingly. It is worth noting that hour incentives can in turn significantly change hour acceptance probabilities; therefore, we need to model the feedback loop between incentives and acceptance rates into a dynamic hour incentive system.
Real-time Capacity
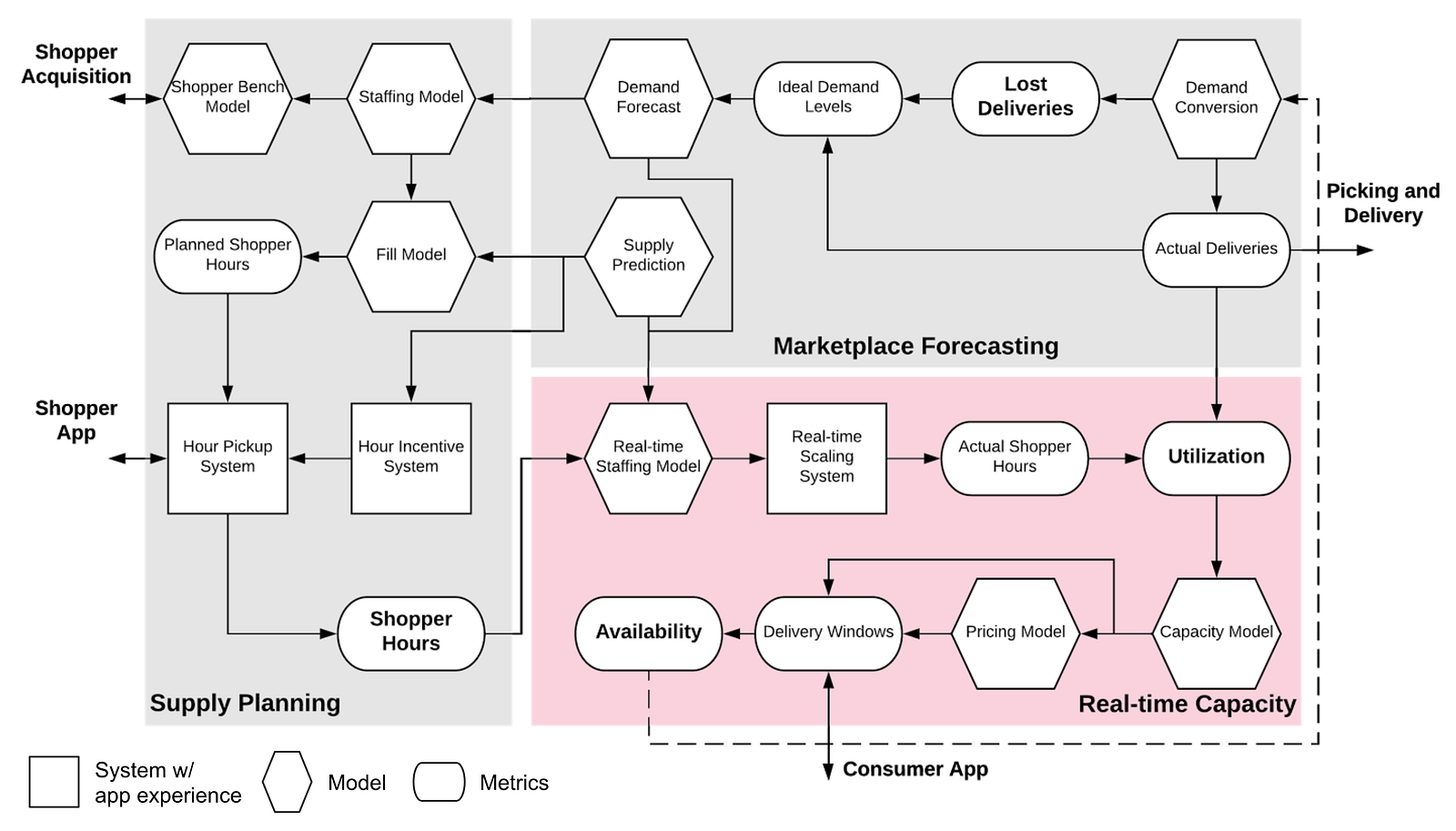
Real-time Capacity serves as the gatekeeper of our system, allowing us to adapt to reality more accurately as we have more data in real time. It includes the following data science problems:
- Real-time Staffing Model: Supply Planning generates shopper hours based on batch predictions made at least one day before hours start, which can sometimes deviate from reality significantly. Real-time staffing model uses real-time demand forecasts, supply predictions, and any supply-demand mismatch to dynamically adjust supply to match demand.
- Capacity Model: This model predicts the number of orders we can fulfill for each delivery window for a given store based on the existing supply and demand levels. We use a machine learning model to trade off between capacity and lateness. If the model estimates capacity too conservatively, it will unnecessarily limit the availability of delivery windows and increase shoppers idleness due to lack of orders. On the other hand, overly aggressive capacity estimation will take too many orders and result in late deliveries, hurting the customer experience.
- Delivery Pricing Model: The capacity model provides insights into how much demand shoppers can serve. Actually, there is more we can do! For example, we price delivery windows differently to shift demand from busy times to idle times. Demand elasticity also depends on other factors such as user types, baskets, etc.; therefore, the demand conversion model is also useful for balancing supply and demand in real time.
This post was a high-level overview of the data science challenges that our team grapples with every day. Stay tuned for upcoming posts from our team to give you a more detailed view of some of these challenges.

Last but not least, our team effort goes beyond data science. We are a multidisciplinary team of data scientists, machine learning engineers, full-stack and mobile engineers, data analysts, designers, and product managers. We learn from each other, collaborate cross-functionally, deliver a powerful impact to Instacart’s business, and strive for Instacart Anytime!
Interested in joining us? Apply here, or contact us!
Appendix: The Instacart Experience
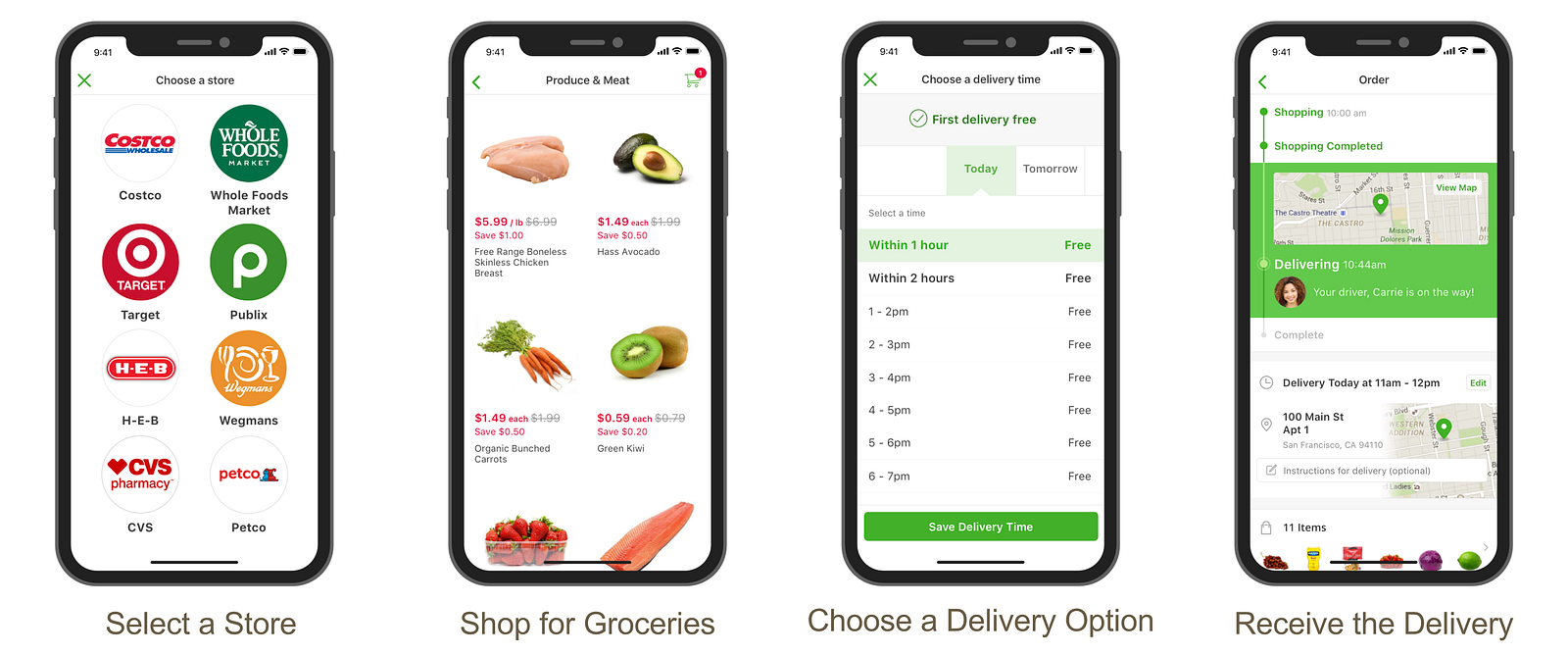
Instacart provides a seamless online grocery shopping experience. As shown above, customers can open the app, select their favorite store, shop for groceries online, choose a delivery window, and receive their groceries within the selected time window, which can be as fast as one hour.

After an order is placed, our system would assign it to a particular shopper. As shown above, the shopper would acknowledge the order, go to the store, find and scan the items on the order list, confirm the items with the customer, and check out for delivery.
Both customer and shopper experiences on Instacart are straightforward; however, the system behind the scenes is very complex (read Space, Time and Groceries by Jeremy Stanley). We want customers can place orders with their desirable delivery windows, and shoppers can be well utilized and deliver the orders efficiently and in time. Every minute counts!
Recommended Courses:
Machine Learning - Fun and Easy using Python and Keras
☞ http://bit.ly/2Ihzd0d
Python Machine Learning Projects
☞ http://bit.ly/2FOfErd
Beginner to Advanced Guide on Machine Learning with R Tool
☞ http://bit.ly/2IiISUy
via : Instacart Anytime: A Data Science Paradigm
Suggest:
☞ Machine Learning Zero to Hero - Learn Machine Learning from scratch
☞ Python Machine Learning Tutorial (Data Science)
☞ Platform for Complete Machine Learning Lifecycle