Learn Python by analyzing Donald Trump’s tweets

In this series of posts, I will share my notes from a Python workshop I held for IEEE earlier this year. The goal of the workshop was to finish a project from scratch. The idea we came up with was to build a tool which can read and analyse Donald Trump’s tweets. Then we can decide whether a specific tweet is presidential or not. So let’s see what Python has to say about this.
Who should read this?
This tutorial is for you if:
- you have a basic understanding of programming, but don’t quite know your way around Python, or
- you know Python but don’t know how to use it to read and analyse textual data from the web.
This is a beginner level tutorial, targeted for people with a very basic understanding of programming.
How to use this tutorial?
In this tutorial, we will start with some simple code, and try to improve on it as we progress. You can copy and paste (or even better, type it out yourself) the code into your text editor, save it, and run it in the Terminal or Command Prompt. Make sure you create a directory somewhere on your machine, and save the files there.
When explaining the code, I introduce some new concepts. You should go through the official documentation to get a deeper understanding of these concepts.
Since this tutorial served as side notes of a workshop, it is rather fast paced. So, the explanations are not as comprehensive as you might find in other tutorials. Thus make sure you consult other resources, or write a comment here, whenever you feel lost. And remember: Google, StackOverflow, and Python official docs are your best friends.
Prerequisites
Make sure you have Python3.6 (or newer) installed.
If you are on a Mac, type python3.6 --version in your Terminal. If you are on Windows, type py --version in the Command Prompt. In either case, you should see your Python version. If you see an error instead, or if the version you see is older than 3.6, it means you need to download and install the newer version.
Moreover, you need to have a good text editor. Any text editor would work. But I recommend something like Atom, since it’s free, open source, and supports Python out of the box.
The first approach
To keep things simple, our first approach is to break down a tweet into words.
first.py
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
tweet_words = tweet_string.split()
number_of_words = len(tweet_words)
print(tweet_words)
print("Number of words in this tweet is: " + str(number_of_words))
# Iterate through the words in the tweet string
print("Words in the tweet are:")
for w in tweet_words:
len_of_w = len(w)
print("number of letters in " + w + " is " + str(len_of_w) )
print("End of the words in the tweet")
As you can see, we have manually copied one of Trump’s tweets, assigned it to a variable, and used the split() method to break it down into words. split() returns a list, which we call tweet_words. We can calculate the number of items in a list using the len function. In lines 4 and 5, we print the results of the previous steps. Pay attention to the str function in line 5. Why is it there?
Finally, in line 9, we loop over tweet_words: that is, we go over tweet_words items one by one, store it in w, and then work with w in lines 10 and 11. So, lines 10 and 11 get executed many times, each one with a different value for w. You should be able to tell what lines 10 and 11 do.
Save this code to a first.py. If you are on Mac or Linux, go to the Terminal. In the folder where you have saved the file, type python3.6 first.py, and hit Enter. On Windows, you need to type py first.py in the Command Prompt.
The second approach
Here, we try to improve our code, so that we can tell if a tweet is “bad” or “good.”
The idea here is to create two lists of good words and bad words, and increase or decrease the value of a tweet based on the number of words it contains from these lists.
"""
To evaluate the good or bad score of a tweet, we count the number of good and
bad words in it.
if a word is good, increase the value of good_words by one
else if a word is bad, increase the value of bad_words by one
if good_words > bad_words then it's a good tweet otherwise it's a bad tweet
"""
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
tweet_words = tweet_string.split()
number_of_words = len(tweet_words)
number_of_good_words = 0
number_of_bad_words = 0
good_words = ["Thanks", "historic", "paychecks"]
bad_words = ["taxes"]
# Iterate through the words in the tweet string
for w in tweet_words:
print(w)
if w in good_words:
number_of_good_words += 1 # same as writing number_of_good_words = number_of_good_words + 1
elif w in bad_words:
number_of_bad_words += 1
print ("There are " + str(number_of_good_words) + " good words in this tweet")
print ("There are " + str(number_of_bad_words) + " bad words in this tweet")
if number_of_good_words > number_of_bad_words:
print ("What a presidential thing to say! HUGE!")
else:
print ("Surely you're joking, Mr. Trump! SAD!")
So, in lines 16 and 17, we initialize two values, each representing the number of good words and bad words in a tweet. In lines 19 and 20, we create our lists of good and bad words. These are, of course, highly subjective lists, so feel free to change these lists based on your own personal opinion.
In line 21, we go over each word in the tweet one by one. After printing it on line 22, we check if the word exists in good_words or bad_words, and increase number_of_good_words or number_of_bad_words, respectively. As you can see, to check whether an item exists in a list, we can use the in keyword.
Also, pay attention to the syntax of if: you need to type a colon (:) after the condition. Also, all the code that should be executed inside if should be indented.
Can you tell what lines 31–34 do?
The third approach
Our assumption so far was that words are either good or bad. But in the real world, words carry varying weights: awesome is better than alright_,_andbadis better thanterrible. So far, our code doesn’t account for this.
To address this, we use a Python data structure called a dictionary. A dictionary is a list of items, with each item having a key and a value. We call such items key-value pairs. So, a dictionary is a list of key-value pairs(sometimes called a key-value store).
We can define a dictionary by putting a list of key:values inside curly braces. Take a look at line 16 in the code below.
"""
To evaluate the good or bad score of a tweet, we first split our tweet.
We then associate each word with positive and negative values, respectively, using a dictionary.
Finally, we caculate the average word weight of a tweet, and decide if it's a good or bad one
based on that.
"""
# Break down a string into words
def get_words(str):
return str.split()
# Iterate through the words in the tweet string
word_weights = {"Thanks": 1.0, "historic": 0.5, "paychecks": 0.8, "taxes": -1.0}
# Calculate the average value of words in list_of_words
def get_average_word_weight(list_of_words):
number_of_words = len(list_of_words)
sum_of_word_weights = 0.0
for w in list_of_words:
if w in word_weights:
sum_of_word_weights += word_weights[w]
return sum_of_word_weights / number_of_words
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
words = get_words(tweet_string)
avg_tweet_weight = get_average_word_weight(words)
print ("There weight of the tweet is " + str(avg_tweet_weight))
if avg_tweet_weight > 0:
print ("What a presidential thing to say! HUGE!")
else:
print ("Surely you're joking, Mr. Trump! SAD!")
As you can see, we are only using a single dictionary. We give bad words a negative value, and good words a positive one. Make sure that the values are between -1.0 and +1.0. Later on, we use our word_weights dictionary in line 23 to check if a word exists in it, and in line 24 to figure out the value assigned to the word. This is very similar to what we did in the previous code.
Another improvement in this code is that it’s better structured: we tried to separate different logical parts of the code into different functions. As you can see in lines 12 and 19, functions are defined with a def keyword, followed by a function name, followed by zero or more arguments inside parentheses. After defining these functions, we use them in lines 29 and 30.
The fourth approach
So far so good. But still, there are some clear shortcomings in our code. For example, we can assume that a noun, whether singular or plural, has the same value. This is not the case here. For example, the words tax and taxes are interpreted as two distinct words, which means we need to have two different entries in our dictionary, one for each. To avoid this kind of redundancy, we can try to stem the words in a tweet, which means to try to convert each word to its root. For example, both tax and taxes will be stemmed into tax.
This is a very complicated task: natural languages are extremely complicated, and building a stemmer takes a lot of time and effort. Moreover, these tasks have been done before. So, why reinvent the wheel, especially such a complicated one? Instead, we will use code written by other programmers, and packaged into a Python module called NLTK.
Installing NLTK
We can run pip install nltk in our command line to install NLTK. However, this will try to install the module on our system globally. This is not good: there might be programs on our system using the same module, and installing a newer version of the same module might introduce problems. Moreover, if we can install all the modules in the same directory where our code resides, we can simply copy that directory and run it on different machines.
So, instead, we start by creating a virtual environment.
First, make sure you’re in the same folder as where your code resides. Then type in the following in the Terminal:
python3.6 -m venv env
and if you’re on Windows, type the following in the Command Prompt:
py -m venv env
This creates a local copy of Python and all it’s necessary tools, in the current folder.
Now, you need to tell your system to use this local copy of Python. On Mac or Linux, use the following command:
source env/bin/activate
And in Windows:
env\Scripts\activate
If you have done everything right, you should see your command prompt changed. Most probably, you should see (env) at the beginning of your command line.
We use pip command to install Python packages. But first, let’s make sure we are using the latest version of pip by running the following command:
pip install --upgrade pip
And, only if you are on Mac, make sure to run the following command as well:
sudo "/Applications/Python 3.6/Install Certificates.command"
Now, you can safely install NLTK using the pip command:
pip install nltk
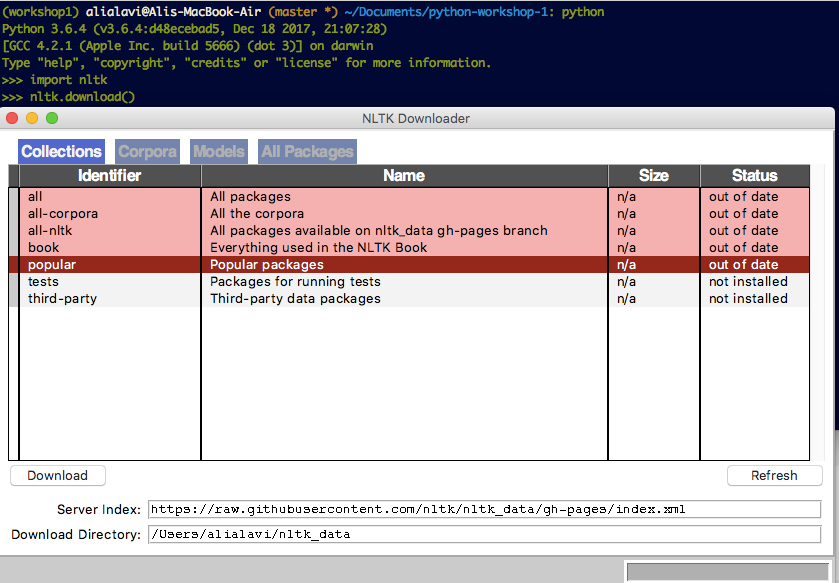
Finally, run your Python interpreter by running python (or py if you are on Windows) and type in the following commands in the interpreter:
import nltk
nltk.download()
A window should pop up. Select the item with popular identifier, and click on download. This will download all the necessary data used by popular NLTK modules.
Now that we’re done with installing NLTK, let’s use it in the code.
Using NLTK
In order to use a module in Python, we need to import it first. It is done in lines 11 where we tell Python we want to use the function word_tokenize, and in line 12, where we say we want to use everything there is in the nltk.stem.porter module.
In line 14, we create a stemmer object using PorterStemmer (guess where it’s defined?), and in line 18, we use word_tokenize instead of split to break down our tweet into words in a smarter way.
Finally, in line 31, we use stemmer.stem to find the stem of the word, and store it in stemmed_word. The rest of the code is very similar to our previous code.
"""
To evaluate the good or bad score of a tweet, we first tokenize the tweet, and then
stemmize each word in our tweet. We also associate each stem with positive and negative values,
respectively, using a dictionary.
Finally, we caculate the average word weight of a tweet, and decide if it's a good or bad one
based on that.
"""
from nltk import word_tokenize
from nltk.stem.porter import *
stemmer = PorterStemmer()
# Break down a string into words
def get_words(str):
return nltk.word_tokenize(str)
# Iterate through the words in the tweet string
word_weights = { "thank": 1.0, "to": 0.0, "the": 0.0, "histor": 0.5, "cut": 0.0, "that": 0.0,
"I": 0.0, "sign": 0.0, "into": 0.0, "law": 0.0, "your": 0.0, "paycheck": 0.0, "way": 0.0, "UP": 0.0,
"your": 0.0, "way": 0.0, "down": 0.0, "and": 0.0, "america": 0.0, "is": 0.0, "onc": 0.0, "again": 0.0,
"open": 0.0, "for": 0.0, "busi": 0.0}
# Calculate the average value of words in list_of_words
def get_average_word_weight(list_of_words):
number_of_words = len(list_of_words)
sum_of_word_weights = 0.0
for w in list_of_words:
stemmed_word = stemmer.stem(w)
if stemmed_word in word_weights:
sum_of_word_weights += word_weights[stemmed_word]
else:
print ('"' + stemmed_word + '": 0.0,')
return sum_of_word_weights / number_of_words
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
words = get_words(tweet_string)
avg_tweet_weight = get_average_word_weight(words)
print ("The weight of the tweet is " + str(avg_tweet_weight))
if avg_tweet_weight > 0:
print ("What a presidential thing to say! HUGE!")
else:
print ("Surely you're joking, Mr. Trump! SAD!")
As you should remember, we use a dictionary of word-to-value dictionary in lines 20 to 24. Having such a long list of words inside our program is a bad practice. Think about it: we need to open and edit our code whenever we decide to change the word-to-value dictionary (like adding a word or changing a word weight). This is problematic because:
- We might mistakenly change other parts of our code.
- The more word we add, the less readable our code becomes.
- Different people using the same code might want to define different dictionaries (e.g. different language, different weights, …), and they cannot do it without changing the code.
For these reasons (and many more), we need to separate the data from the code (generally, it’s a good practice). In other words, we need to save our dictionary in a separate file, and then load it in our program.
Now, as you might know, files have different formats, which tells how the data is stored in a file. For example, JPEG, GIF, PNG, and BMP are all different image formats, telling how to store an image in a file. XLS and CSV are also two formats for storing tabular data in a file.
In our case, we want to store a key-value data structure. JSON data format is the most commonly used data format for storing these kinds of data. Moreover, JSON is a popular format for data communication over the world wide web (later on, we will see an examples of this). Here is an example of a JSON file:
{
"firstName": "John",
"lastName": "Smith",
"age" : 25
}
As you can see, it looks just like a Python dictionary. So, go ahead and create a new file, and call it “word_weights.json”. Here is mine:
{
"thank": 1.0,
"to": 0.0,
"the": 0.0,
"histor": 0.5,
"cut": 0.0,
"that": 0.0,
"I": 0.0,
"sign": 0.0,
"into": 0.0,
"law": 0.0,
"your": 0.0,
"paycheck": 0.0,
"way": 0.0,
"UP": 0.0,
"your": 0.0,
"way": 0.0,
"down": 0.0,
"and": 0.0,
"america": 0.0,
"is": 0.0,
"onc": 0.0,
"again": 0.0,
"open": 0.0,
"for": 0.0,
"busi": 0.0
}
word_weights.json
Now, all we need to do is to tell Python to load this file into word_weights.
Opening a file
In order to open a file, we use the [open](https://docs.python.org/3/library/functions.html#open) function. It opens a file and returns a file object, which lets us perform operations on the file. Whenever we open a file, we need to [close](https://docs.python.org/3/library/io.html?highlight=close#io.IOBase.close) it. This ensures that all the operations on the file object are flushed (applied) to the file.
Here, we want to load the file content and assign it to a variable. We know the content of our file is in JSON format. So all we need to do is to import Python’s json module, and apply its load function on our file object:
f = open('sample.json')
myJson = json.load(f)
f.close()
But explicit use of close can be problematic: in a big program, it’s easy to forget to close the file, and it might happen that close is inside a block which is not executed all the time (for example an if).
To avoid such problems, we can use the with keyword. with takes care of closing the file.
with open('sample.json') as f:
myJson = json.load(f)
openFileWith.py
So, when the code exits the with block, the file opened using with is automatically closed. Make sure you always use the with coding pattern when dealing with files. It’s easy to forget to close a file, and it might introduce many problems.
Take a look at lines 22 to 24:
"""
To evaluate the good or bad score of a tweet, we first tokenize the tweet, and then
stemmize each word in our tweet. We also associate each stem with positive and negative values,
respectively, using a dictionary.
Finally, we caculate the average word weight of a tweet, and decide if it's a good or bad one
based on that.
"""
import json
from nltk import word_tokenize
from nltk.stem.porter import *
stemmer = PorterStemmer()
# Break down a string into words
def get_words(str):
return word_tokenize(str)
# Initialize word weights and read them from word_weights.json
word_weights = {}
with open("word_weights.json") as f: # open the json file, and put its handler in variable f
word_weights = json.load(f) # read the content of the file into
# Calculate the average value of words in list_of_words
def get_average_word_weight(list_of_words):
number_of_words = len(list_of_words)
sum_of_word_weights = 0.0
for w in list_of_words:
stemmed_word = stemmer.stem(w)
if stemmed_word in word_weights:
sum_of_word_weights += word_weights[stemmed_word]
else:
print ('"' + stemmed_word + '": 0.0,')
return sum_of_word_weights / number_of_words
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
words = get_words(tweet_string)
avg_tweet_weight = get_average_word_weight(words)
print ("The weight of the tweet is " + str(avg_tweet_weight))
if avg_tweet_weight > 0:
print ("What a presidential thing to say! HUGE!")
else:
print ("Surely you're joking, Mr. Trump! SAD!")
fifth.py
We can further improve this code, by turning loading JSON files and analysing tweets into two functions. Look at lines 20–23, and 41–49:
"""
To evaluate the good or bad score of a tweet, we count the number of good and
bad words in it.
if a word is good, increase the value of good_words by one
else if a word is bad, increase the value of bad_words by one
if good_words > bad_words then it's a good tweet otherwise it's a bad tweet
"""
import json
import nltk
from nltk.stem.porter import *
stemmer = PorterStemmer()
# Break down a string into words
def get_words(str):
return nltk.word_tokenize(str)
# Load a json object from a file
def load_json(json_file):
with open(json_file) as f:
return json.load(f)
# Calculate the average value of words in list_of_words
def get_average_word_weight(list_of_words, word_weights):
number_of_words = len(list_of_words)
sum_of_word_weights = 0.0
if number_of_words == 0:
return 0.0
# Iterate through the words in the tweet string
for w in list_of_words:
stemmed_word = stemmer.stem(w)
if stemmed_word in word_weights:
sum_of_word_weights += word_weights[stemmed_word]
#else:
#print ('"' + stemmed_word + '": 0.0,')
return sum_of_word_weights / number_of_words
def anaylse_tweet(tweet_string, word_weights):
words = get_words(tweet_string)
avg_tweet_weight = get_average_word_weight(words, word_weights)
print ("The weight of the tweet is " + str(avg_tweet_weight))
if avg_tweet_weight > 0:
print ("What a presidential thing to say! HUGE!")
else:
print ("Surely you're joking, Mr. Trump! SAD!")
tweet_string = "Thanks to the historic TAX CUTS that I signed into law, your paychecks are going way UP, your taxes are going way DOWN, and America is once again OPEN FOR BUSINESS!"
word_weights = load_json("word_weights.json")
anaylse_tweet(tweet, word_weights)
sixth.py
Now, all our program does is that it assigns a tweet string (line 51), loads a dictionary of word weights (line 52), and analyses that tweet string using the loaded dictionary.
Reading the tweets from Twitter
In order to read data from Twitter, we need to access its API (Application Programming Interface). An API is an interface to an application which developers can use to access the application’s functionality and data.
Usually, companies such as Twitter, Facebook, and others allow developers to access their user data via their APIs. But as you might know, user data is extremely valuable to these companies. Moreover, many security and privacy concerns come into play when user data is involved. Thus, these companies want to track, authenticate, and limit the access of developers and their applications to their API.
So, if you want to access Twitter data, first you need to sign in to Twitter (and sign up if you don’t have a Twitter account), and then go to https://apps.twitter.com/. Click on the Create New App button, fill out the form, and click on Create your Twitter Application button.
In the new page, select the API Keys tab, and click on Create my access token button. A new pair of Access token, Access token secretwill be generated. Copy these values, together with the API keyand API secretsomewhere.
Now, start up your Terminal or Command Prompt, go to your working directory, and activate your virtual environment (reminder: if you are on Mac/Linux run . env/bin/activate and if you are on Windows run env/Scripts/activate ). Now, install the python-twitter package using pip:
pip install --upgrade pip
pip install python-twitter
This installs a popular package for working with the Twitter API in Python.
Now, let’s quickly test our setup.
Run your Python interpreter by typing python (or py if you are on Windows). Type in the following, and replace YOUR_CONSUMER_KEY, YOUR_CONSUMER_SECRET, YOUR_ACCESS_TOKEN, and YOUR_ACCESS_TOKEN_SECRET with the values you copied in the previous step:
import twitter
twitter_api = twitter.Api(consumer_key="YOUR_CONSUMER_KEY",
consumer_secret="YOUR_CONSUMER_SECRET",
access_token_key="YOUR_ACCESS_TOKEN",
access_token_secret="YOUR_ACCESS_TOKEN_SECRET",
tweet_mode='extended')
twitter_api.VerifyCredentials()
We can also get tweets of a user using the GetUserTimeline method the Twitter API. For example, in order to get the last tweet from Donald Trump, just use the following:
last_tweet = twitter_api.GetUserTimeline(screen_name="realDonaldTrump", count=10)
This will give us a list with one item, containing information about Trump’s last tweet. We can get different information about the tweet. For example, last_tweet.full_text will give us the full text of his last tweet.
Using the knowledge we gained about the Twitter API, we can now change our code to load the tweet string from Twitter. Take a look at lines 54 to 72:
"""
To evaluate the good or bad score of a tweet, we first tokenize the tweet, and then
stemmize each word in our tweet. We also associate each stem with positive and negative values,
respectively, using a dictionary.
Finally, we caculate the average word weight of a tweet, and decide if it's a good or bad one
based on that.
"""
import json
import html
import twitter
import time
from nltk import word_tokenize, pos_tag
from nltk.stem.porter import *
# Break down a string into words
def get_words(str):
useful_pos = {'NN'}
tokens = word_tokenize(str)
tags = pos_tag(tokens)
return [word for word, pos in tags if pos in useful_pos]
# Load a json object from a file
def load_json(json_file):
with open(json_file) as f:
return json.load(f)
# Calculate the average value of words in list_of_words
def get_average_word_weight(list_of_words, word_weights):
number_of_words = len(list_of_words)
sum_of_word_weights = 0.0
print (number_of_words)
if number_of_words == 0:
return 0.0
stemmer = PorterStemmer()
# Iterate through the words in the tweet string
for w in list_of_words:
stemmed_word = stemmer.stem(w)
if stemmed_word in word_weights:
sum_of_word_weights += word_weights[stemmed_word]
#else:
#missing_words[stemmed_word] = 0.0
return sum_of_word_weights / number_of_words
# Analyse a tweet using a word-weight dictionary
def anaylse_tweet(tweet_string, word_weights):
words = get_words(tweet_string)
avg_tweet_weight = get_average_word_weight(words, word_weights)
print (tweet_string + ":" + str(avg_tweet_weight))
# Load word weights and credentials from json files
word_weights = load_json("word_weights.json")
credentials = load_json(".cred.json")
# Connect to the twitter api
twitter_api = twitter.Api(consumer_key=credentials["consumer_key"],
consumer_secret=credentials["consumer_secret"],
access_token_key=credentials["access_token_key"],
access_token_secret=credentials["access_token_secret"],
tweet_mode='extended')
# Load last 10 statuses of Donald Trump
statuses = twitter_api.GetUserTimeline(screen_name="realDonaldTrump", count=10)
# Iterate through them and analyse them
for status in statuses:
anaylse_tweet(html.unescape(status.full_text), word_weights)
Of course, as discussed before, storing data inside code is a bad practice. It is especially bad when that data involves some kind of secret. But we know how to do it properly, right? So, in line 56 we load our Twitter credentials from .cred.json file. Just create a new JSON file, store your keys and secrets inside a dictionary, and save it as .cred.json:
{
"consumer_key": "YOUR CONSUMER KEY",
"consumer_secret": "YOUR CUSTOMER SECRET",
"access_token_key": "YOUR ACCESS TOKEN KEY",
"access_token_secret": "YOUR ACCESS TOKEN SECRET"
}
You should be able to understand the new code, except maybe line 70. As you know, many tweets contain non-alphabetic characters. For example, a tweet might contain &, > or<. Such characters are escaped by the Tweeter. It means that Twitter converts these characters to HTML-safe characters.
For example, a tweet like Me & my best friend <3 is converted to Me & my best friend <3 . In order to convert this back to its original representation, we need to unescapeour tweets, using the **unescape** function from the **html** module. This is what happens on line 70.
Try to run this code. You should be able to decide if Trump’s latest tweets were presidential or not.
Share your thoughts, and show this post some ❤ if you will.
Recommended Courses:
Python Programming Fundamentals
☞ http://bit.ly/2uGy8Ht
Volatility Trading Analysis with Python
☞ http://bit.ly/2JP5J6A
Step by Step Python Programming : 50+ Programming exercise
☞ http://bit.ly/2mDLoIf
2017 Python Pandas: connect & import directly any database
☞ http://bit.ly/2LNC6EQ
Suggest:
☞ Python Tutorials for Beginners - Learn Python Online
☞ What is Python and Why You Must Learn It in [2019]
☞ Learn Python in 12 Hours | Python Tutorial For Beginners
☞ Complete Python Tutorial for Beginners (2019)
☞ Python Programming Tutorial | Full Python Course for Beginners 2019