Python so slow? Here’s how you can make them 7x faster.

Why is Python slow?
The default implementation of Python ‘CPython’ uses GIL (Global Interpreter Lock) to execute exactly one thread at the same time, even if run on a multi-core processor as GIL works only on one core regardless of the number of cores present in the machine. Each core in the CPU has its own GIL, so a quad-core CPU will have 4 GILs running separately with its own interpreter. To make our python programs run parallel we use multithreading and multiprocessing.
Multithreading does not make much of a difference in execution time as it uses the same memory space and a single GIL, so any CPU-bound tasks do not have an impact on the performance of the multi-threaded programs as the lock is shared between threads in the same core and only one thread is executed while they are waiting for other tasks to finish processing. Also, threads use the same memory so precautions have to be taken or two threads will write to the same memory at the same time. This is the reason why the global interpreter lock is required.
Multiprocessing increases the performance of the program as each Python process gets its own Python interpreter and memory space so the GIL won’t be a problem. But also increases process management overheads as multiple processes are heavier than multiple threads. Also, we need to share objects from one memory to the other everytime we update objects in one memory since the memory isn’t linked with each other and are performing tasks separately.
Is GIL the problem causing agent? Why don’t we remove it?
Since the GIL allows only one thread to execute at a time even in a multi-threaded architecture with more than one CPU core, the GIL has gained a reputation as an “infamous” feature of Python. Thus this limits the execution speed of Python programs and does not utilize provided resources to its fullest.
So why don’t we remove GIL? CPython uses reference counting for memory management. It means that objects created in CPython have a reference count variable that keeps track of the number of references that point to the object. When this count reaches zero, the memory occupied by the object is released.
If we remove GIL from CPython than the reference count variable will not be protected anymore as two threads may increase or decrease its value simultaneously. And if this happens, it can cause either leaked memory that is never released or, even worse, incorrectly releasing the memory while a reference to that object still exists. This can cause crashes or other “weird” bugs in our Python programs.
Also, there have been a few attempts to remove the GIL from CPython, but the extra overhead for single threaded machines was generally too large. Some cases can actually be slower even on multi-processor machines due to lock contention.
There are alternatives approaches to GIL such as Jython and IronPython which use the threading approach of their underlying VM, rather than a GIL approach.
To conclude GIL is not much of a problem to us right now as Python programs with a GIL can be designed to use separate processes to achieve full parallelism, as each process has its own interpreter and in turn, has its own GIL.
Benefits of having GIL in Python implementation:
- Increased speed of single-threaded programs.
- Easy integration of C libraries that usually are not thread-safe.
- Easy implementation as having a single GIL is much simpler to implement than a lock-free interpreter or one using fine-grained locks.
Is Python slow due to its dynamic nature?
We all know Python as a dynamically-typed programming language where we don’t need to specify variable data types while assigning variables. The data type is assigned to the variable at the runtime so every time the variable is read, written or referenced its data type is checked and the memory is allocated accordingly.
Whereas statically-typed programming languages have an advantage over this as the datatypes are already known so they don’t need to check the datatype everytime the variable is used in the program. This thus saves them a lot of time and makes the entire execution faster.
The design of the Python language enables us to make almost anything dynamic. We can replace the methods on objects at runtime, we can monkey-patch low-level system calls to a value declared at runtime. Almost anything is possible. So not having to declare the type isn’t what makes Python slow, it’s this design that makes it incredibly hard to optimize Python.
“CPython is interpreted at runtime.” Is this an issue for slow execution of Python programs?
As soon as we run our Python program, the source code .py file is first compiled using CPython (written in ‘C’ programming language) into intermediate bytecode .pyc file saved in __pycache__ folder (Python 3) and then interpreted by Python Virtual Machine to Machine code.
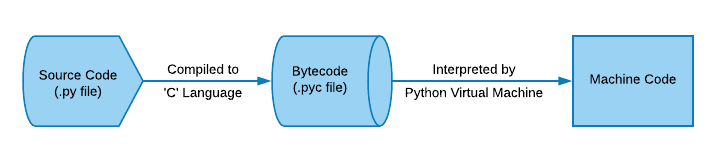
Since CPython uses an interpreter which executes the generated bytecode directly at runtime, this makes the execution a lot slower as each line is interpreted while execution of the program. Whereas other programming languages like C, C++ are directly compiled into machine code before the execution takes place using Ahead of time (AOT) compilation. Also, Java compiles to an ‘Intermediate Language’ and the Java Virtual Machine reads the bytecode and just-in-time (JIT) compiles it to machine code. The .NET Common Intermediate Language (CIL) is the same, the .NET Common-Language-Runtime (CLR), uses just-in-time (JIT) compilation to machine code.
We understand that AOT compilation is faster than interpretation as the program has already been compiled into the machine-readable code before any execution takes place. But how does JIT compilation manage to run programs faster than CPython implemented programs?
JIT compilation is a combination of the two traditional approaches to translation to machine code — ahead-of-time compilation (AOT), and interpretation — and combines some advantages and drawbacks of both. So JIT compilation optimizes our program by compiling certain parts of the program which are used frequently and is further executed with the rest of the code at the runtime of the program.
Some implementations of Python like PyPy uses JIT compilation which is more than 4 times faster than CPython. So why does CPython not use JIT?
There are downsides to JIT as well, one of those is a startup time delay. Implementations using JIT have a significantly slower boot time as compared to CPython. CPython is a general-purpose implementation for developing Command Line (CLI) programs and projects which do not require much heavy-lifting from the CPU. There was a possibility for using JIT in CPython but has largely been stalled due to its hard implementation and lack of flexibility in Python.
“If you want your code to run faster, you should probably just use PyPy.” — Guido van Rossum (creator of Python)
What’s the alternative for CPython?
PyPy is claimed to be the fastest implementation for Python with the support of popular Python libraries like Django and is highly compatible with existing Python code. PyPy has a GIL and uses JIT compilation so it combines the advantages of both making the overall execution a lot faster than CPython**.** Several studies have suggested that it is about 7.5 times faster than CPython.
How does PyPy work?
PyPy first takes our Python source code and converts it to RPython which is a statically-typed restricted subset of Python. RPython is easier to compile into more efficient code as its a statically-typed language. PyPy then translates the generated RPython code into a form of bytecode, together with an interpreter written in the ‘C’ programming language. Much of this code is then compiled into machine code, and the bytecode runs on the compiled interpreter.
Here’s a visual representation of this implementation:
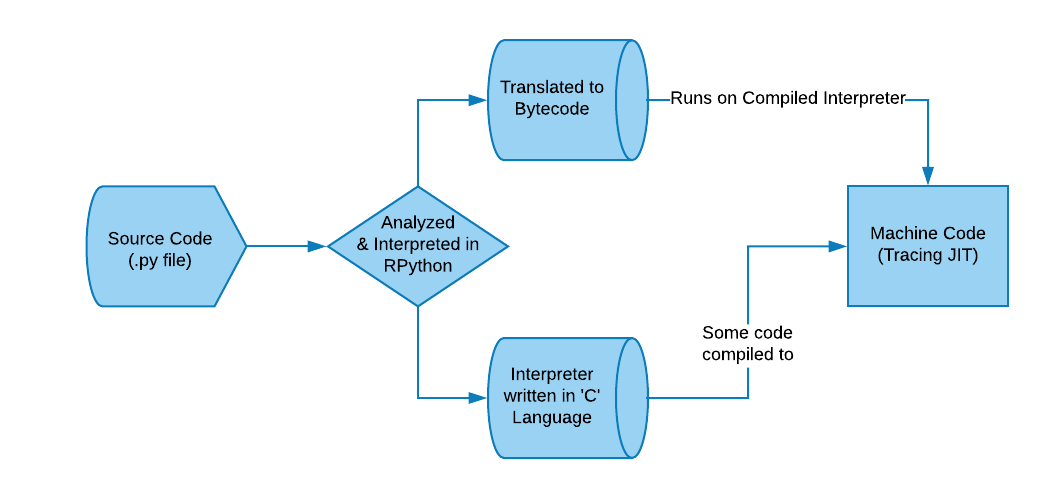
It also allows for pluggable garbage collectors, as well as optionally enabling Stackless Python features. Finally, it includes a just-in-time (JIT) generator that builds a just-in-time compiler into the interpreter, given a few annotations in the interpreter source code. The generated JIT compiler is a tracing JIT.
This was a brief explanation of how the implementation works, if you are curious to know more about PyPy, then you can read more here.
Why don’t we use PyPy as a standard implementation in Python?
As we discussed the downside of JIT being its startup time delay, PyPy follows the suite. Also, PyPy is incompatible for many C-Extensions because CPython is written in ‘C’ programming language and third-party extensions on PyPI take advantage of this. Numpy would be a good example, much of Numpy is written in optimized C code. When we pip install numpy, it uses our local C compiler and builds a binary library for our Python runtime to use.
PyPy is written in Python so we need to make sure that modules required for our project are supported by PyPy before implementing it in our project.
These were the reasons for not using PyPy as a default implementation in Python. Apart from PyPy, There are many other implementations available for Python which can be used alternatively to make Python run faster so you can choose the one whichever suits you the best.
Conclusion
The findings that I have presented suggest that Python is indeed a slow language due to its dynamic nature compared to other statically-typed languages like C, C++, Java. But, should we care about it much?
Probably not, as we all know how much development time is saved by using Python in our projects. Startups are already using Python extensively for their projects just to get their product in the market as soon as possible. This saves them a lot of labor cost and man-hours spent on a single product. Frameworks like Django have made full stack development possible with a lot of essential features already provided to them.
Python developers are now employing optimal implementation for Python if performance is a constraint to them while working on Machine Learning, Big Data, Artificial Intelligence as a whole. Possibilities are endless when it comes to using a modern and dynamic language with vast support of more than 100,000 libraries available in Python Package Index (PyPI) today. This makes developers work easier as well as faster at the same time.
Further Reading
If you’d like to learn more about Python GIL, Python implementations, Python bytecode and how do they work, I recommend these resources:
- You can check more about Python implementations from the Python wiki page for various Python implementations available.
- If you want to know how Python Bytecode works exactly, then this is the best resource I have found so far.
- Also, do check out David Beazley’s talk on Understanding the Python GIL 2012 video version.
- You may also check out the previous 2009 PDF version of David Beazley’s talk on Inside the GIL
- If you are curious to learn more about PyPy then you can get started with this PyPy documentation.
Further reading:
☞ PyTorch 1.0: Now and in the Future
☞ Text-based snake and ladder game in python
☞ 5 common mistakes made by beginner Python programmers
☞ 15 articles you must read If you are building a website in Python Django
Suggest:
☞ Python Tutorials for Beginners - Learn Python Online
☞ Learn Python in 12 Hours | Python Tutorial For Beginners
☞ Complete Python Tutorial for Beginners (2019)
☞ Python Programming Tutorial | Full Python Course for Beginners 2019