Parallelisation In Python — An Alternative Approach

one of the biggest, ever-present banes of a data scientist’s life is the constant wait for the data processing code to finish executing. The problem with slow code affects almost every step of a typical data science pipeline: data collection, data pre-processing/parsing, feature engineering, etc. Many times, the gigantic execution times even end up making the project infeasible and more often than desired, forces a data scientist to work with only a subset of data, depriving him/her of the insights and performance improvements that could be obtained with a larger dataset.
One of the tools that could mitigate this problem and speed up data science pipelines is parallelisation through multiprocessing or multithreading.
In this blogpost, I am sharing my experience of solving a data collection problem by using an approach that utilizes multiprocessing with python. The main achievement of this exercise was the development of a general approach for parallelisation wherein a code template was created and used. Using the approach, I was able to reduce the execution time from several days to under an hour for a practical problemdiscussed in this blog**.** The same code template has been tested for other use cases and has proven to be effective.
The Vanilla approach to parallelisation
This is the usual way parallelisation is applied in python.
- Get a list of all items for which the same task needs to be performed independent of other items.
- Workers execute in parallel and each worker applies the task logic to a single item in this list and obtains the result for this specific item.
- After a worker finishes the task on a single item, it picks up another item from the global list of items and applies the task logic to it.
- The process goes on until the list of items gets exhausted.
The Splitting approach to parallelisation (New)
This is the new parallelisation approach.
- Get a list of all items for which the same task needs to be performed independent of other items.
- Divide the list of items into sublists.
- Pass one sublist to each worker/thread so that each worker/thread iterates over its own sublist in a serial manner and performs the required task.
The workers themselves execute in parallel. Thus, even though each worker is performing the task in a serial manner, the workers are working simultaneously on their own sublist of tasks and hence, parallelisation is achieved as the net effect. Therefore, the approach is actually a mix of parallel and serial processing.
In contrast, the Serial approach works as follows:
- Get a list of all items for which the same task needs to be performed.
- Pick up an item in the list and execute the task for this item.
- Pick up the next item in the list. The process goes on until the list gets exhausted.
Problem Description
For one of my recent projects, I was faced with the problem of downloading a huge number of emails from a mail server (~3 million). An attempt to download the mails serially resulted in 100k emails being downloaded after 5 days of run time. The email download time clearly needed to be reduced for which parallelisation seemed like an obvious candidate.
For the purpose of code demonstration, I am downloading emails from a public imap (created a fake email id on yandex and filled it with 1200 emails) using Multiprocessing with the splitting approach. Later on, the same task is going to be performed with all the variants described above as well (code not shown for these in the post). My machine is a MacBook Pro with 2.8 GHz i7 quad core processor.
Multiprocessed splitting
- Get a list of all mail ids present in the mail box after establishing connection with the imap server.
- Select the number of multiprocessing workers (I generally set this to twice the number of logical cores on my machine).
- Divide the list of mail-ids into sublists.
- Launch multiple processes where each process corresponds to a worker and has a sublist of items it must operate upon. Each process establishes an independent connection with the imap server and calls a function that performs the download.
- Each worker downloads the mails serially using the sublist of mail-ids it possesses.
Let us develop the logic for each of these steps:
1. Get a list of all mail ids present in the mail box after establishing a single connection with the imap server.
step_1.py
def connect():
''' This function is used to establish connection with the imap server. '''
counter = 5 # retry counter in case connection does not succeed in the first try.
while counter > 0:
try:
M = imaplib.IMAP4_SSL(IMAP_SERVER) # imaplib, ssl required
M.login(EMAIL_ACCOUNT, PASSWORD)
print('Login success!')
break
except (ssl.SSLEOFError, imaplib.IMAP4.abort) as e:
print('Login fail!')
counter -= 1
continue
return M
# Do a single connection and get all ids
def get_all_ids():
M = connect()
_, _ = M.select()
rv, ids = M.search(None, "ALL")
return ids
ids = get_all_ids()
2. Select the number of multiprocessing workers (I generally set this to twice the number of logical cores on my machine).
NUM_WORKERS = multiprocessing.cpu_count() * 2
3. Divide the list of mail-ids into sublists.
step3.py
def splitter(list_ids, NUM_WORKERS):
list_list_ids = []
for i in np.array_split(list_ids, NUM_WORKERS): # numpy required
list_list_ids.append(list(i))
return list_list_ids
list_ids = ids[0].split() # getting a list from the ids received in step 1
list_list_ids = splitter(list_ids, NUM_WORKERS)
4. Launch multiple processes where each process corresponds to a worker and has a sublist of items it must operate upon. Each process establishes an independent connection with the imap server and calls a function that performs the download.
step_4.py
def mp_process(sublist):
''' A wrapper function within which a particular worker establishes a connection with
the imap server and calls the function to download emails corresponding to the list
of ids for this particular worker.
'''
process_imap = connect()
_, _ = process_imap.select()
return perform_download(process_imap, sublist)
def get_mails(ids, poolsize):
''' A function to initialize the pool of workers and call the wrapper function mp_process.
The input 'ids' is a list of sublists'''
pool = multiprocessing.Pool(poolsize) # multiprocessing package required
s = pool.map(mp_process, ids)
print('Active children count: %d'%len(multiprocessing.active_children()))
pool.close()
pool.join()
return 'OK'
The get_mails function launches a pool of workers and passes a list of sublists to mp_process function such that each worker gets one sublist of mail-ids to process. Virtually, each worker is executing its own copy of the mp_process function with its own specific sublist of mail-ids that it needs to download. All the workers execute in a parallel fashion with no dependence on each other.
5. Each worker downloads the mails serially using the sublist of mail-ids it possesses.
step_5.py
def perform_download(M, sublist_of_ids):
for c in sublist_of_ids: # iteration over the sublist of mail-ids
_, data = M.fetch(c.decode(), '(RFC822)')
f = open('%s/%s.eml' % (OUTPUT_DIRECTORY, str(c.decode())), 'wb')
f.write(data[0][1])
f.close()
M.close()
M.logout()
print('Connection closed!')
This function iterates over the sublist of mail-ids it receives from its calling process and begins downloading the sublist serially.
The complete code can be found in the appendix.
The general template that can be reused and adapted to various tasks is:
parallelsation_template.py
def helper_functions_specific_to_task() # connect()
def actual_task(sublist_of_items) # perform_download()
def wrapper_function(sublist_of_items) # mp_process()
def pool_initializer(list_of_all_items, poolsize) # get_mails()
def splitter(list_of_all_items, NUM_WORKERS) # splitter()
def get_list_of_items() # get_all_ids()
EXPERIMENTS
Several methods were compared in terms of execution time:
- Serial download (Serial).
- Multiprocessing download using the vanilla approach (MP-V).
- Multiprocessing download using the splitting approach (code shown above) (MP-Sp).
- Multithreaded download using the vanilla approach (Mth-V).
- Multithreaded download using the splitting approach (Mth-Sp).
The number of threads/workers were also varied across different runs of multithreading/multiprocessing approaches (X-axis of the graph below).
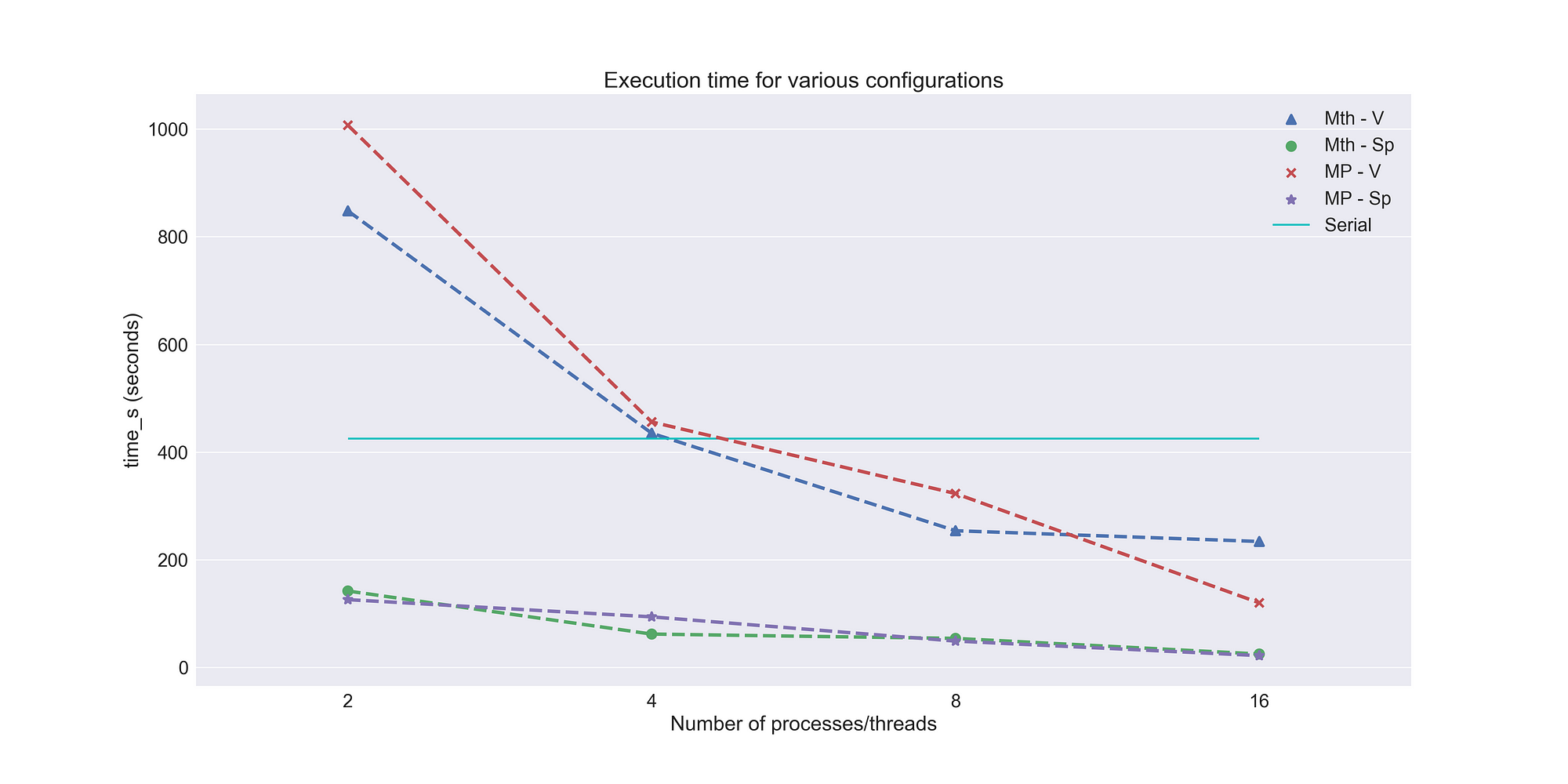
RESULTS
The following conclusions can be drawn from the experiments:
- The splitting approach always outperforms the vanilla approach and the serial approach regardless of the number of workers/threads.
- The vanilla approach performs worse than the serial approach if the number of threads/workers are less than 8.
- There is no real difference between the performance of multithreading and multiprocessing.
- The vanilla approach tends to give better gains in terms of execution time as the number of workers/threads increase compared to the splitting approach. (Further experiments were carried out so that the vanilla approach uses more workers/threads, but the splitting approach was always better even when it used fewer workers/threads.)
Therefore, using a small number of workers/threads with the splitting approach ensures the quick completion of a task while only occupying a small amount of resources.
SUMMARY
An alternative approach of splitting item list into sublists for achieving better parallelisation in python was introduced and shown to be better than the usual approach wherein each item in the list is picked and processed by workers/threads. A practical example was used to demonstrate the performance improvement with the use of the splitting approach. Furthermore, a template to use this approach was developed which makes it possible to apply it regardless of the nature of the underlying task.
APPENDIX
complete_code_2.py
import os
import time
import sys
import ssl
import imaplib
import multiprocessing
import numpy as np
# Credentials and paths
IMAP_SERVER = "imap.yandex.com" # imap server for yandex, choose the one you wish to use.
EMAIL_ACCOUNT = "" # enter the credentials
PASSWORD = ""
OUTPUT_DIRECTORY = os.path.join(os.path.dirname(os.path.abspath(__file__)), '..', 'downloaded_emails') # save mails here
# To parallelise:
'''1. each worker connects individually with the imap server.
2. each worker has a sublist of emails (ids/counts) it should download.
3. each worker then downloads every email in their sublist of ids and terminates'''
def connect():
'''
This function is used to establish connection with the imap server.
'''
counter = 5 # retry counter in case connection does not succeed in the first try.
while counter > 0:
try:
M = imaplib.IMAP4_SSL(IMAP_SERVER)
M.login(EMAIL_ACCOUNT, PASSWORD)
print('Login success!')
break
except (ssl.SSLEOFError, imaplib.IMAP4.abort) as e:
print('Login fail!')
counter -= 1
continue
return M
def splitter(list_ids, NUM_WORKERS):
list_list_ids = []
for i in np.array_split(list_ids, NUM_WORKERS):
list_list_ids.append(list(i))
return list_list_ids
def perform_download(M, sublist_of_ids):
for c in sublist_of_ids: # iteration over the sublist of mail-ids
_, data = M.fetch(c.decode(), '(RFC822)')
f = open('%s/%s.eml' % (OUTPUT_DIRECTORY, str(c.decode())), 'wb')
f.write(data[0][1])
f.close()
M.close()
M.logout()
print('Connection closed!')
def mp_process(sublist):
''' A wrapper function within which a particular worker establishes a connection with
the imap server and calls the function to download emails corresponding the list of
ids for this particular worker.
'''
process_imap = connect()
_, _ = process_imap.select()
return perform_download(process_imap, sublist)
def get_mails(ids, poolsize):
''' A function to initialize the pool of workers and call the wrapper function mp_process.
The input 'ids' is a list of sublists'''
pool = multiprocessing.Pool(poolsize)
s = pool.map(mp_process, ids)
print('Active children count: %d ' %len(multiprocessing.active_children()))
pool.close()
pool.join()
return 'OK'
# Do a single connection and get all ids
def get_all_ids():
M = connect()
_, _ = M.select()
rv, ids = M.search(None, "ALL")
return ids
if __name__ == '__main__':
ids = get_all_ids()
print('Getting into multiprocessing part')
# Define number of workers to be 2*CPU
NUM_WORKERS = multiprocessing.cpu_count() * 2
print('worker count: %d' % NUM_WORKERS)
# splitting the mails ids into chunks of len_each_block mail ids.
list_ids = ids[0].split()
list_list_ids = splitter(list_ids, NUM_WORKERS)
# call multiprocessing function
t1 = time.time()
get_mails(list_list_ids, NUM_WORKERS) # splitting and controlling process count (Faster)
print(time.time() - t1)
ADDITIONAL QUIRKS
- The experiments were carried out on a rather small set of data (only 1200 emails with 2KB per email). It is possible that vanilla approach could outperform the splitting approach for much larger datasets (Splitting approach seemed promising with the initial experimentation, so I ended up choosing it for my final task which involved downloading hundreds of Gigabytes of data across 3 million mails).
- Multiprocessing vs. Multithreading: As can be seen from the results, these two approaches performed similarly. However, as far as python is concerned, Global Interpreter Lock (GIL) usually ends up hampering the multithreading performance and it is usually difficult to ascertain the usability of multithreading for a given use case in python. Multiprocessing, on the other hand, suffers from no such drawbacks and hence, I tend to prefer multiprocessing over multithreading in most cases. But then again, multiprocessing eats up a lot more resources than multithreading, so there’s usually a trade-off between multiprocessing and multithreading when it comes to python. (I chose multiprocessing for my final task).
- Several runs were done for each experiment. During one of the runs, a strange behaviour was observed with the vanilla approach (for both multithreading and multiprocessing) — About 95% of tasks got executed rather quickly, but the last 5% took an extremely long time to finish. This issue wasn’t reproduced.
Suggest:
☞ Python Machine Learning Tutorial (Data Science)
☞ Python Tutorial for Data Science
☞ Machine Learning Zero to Hero - Learn Machine Learning from scratch
☞ Learn Python in 12 Hours | Python Tutorial For Beginners