NodeJS: Best Practices for Production

I have been working on this technology for a while myself. I realize its huge potential and place in the development process. With tough competition from languages like Python and Golang, NodeJS has proven its utility in appropriate use cases.
Before I delve into the best practices 😬, I would like to do a brief introduction to what a microservice pattern is. Then take the conversation further from there.

So, what are microservices?
Microservices - also known as the microservice architecture - is an architectural style that structures an application as a collection of services that are:
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities.
The microservice architecture enables the continuous delivery/deployment of large, complex applications. It also enables an organization to evolve its technology stack.
How to decide if you need microservices
Initially, when you are just starting out to work on your MVP, you might not need to use microservices. The Y-axis scaling might not be your agenda right now. But when the product starts to mature and sometimes too early where you have to deal with scaling, the decomposition into functional modules makes more sense as the business itself is decomposing. This will be the right point to start looking into the microservices architecture pattern.
A book that I highly recommend is by Chris Richardson here: http://bit.ly/2EmJDYt.
Microservices are most commonly considered while replacing a monolithic application that used to be pretty common until recently when containerization solutions like Docker started ruling the DevOps world. But more on that later.
It would be unfair if I continue without mentioning Domain Driven Design (DDD). It is a very popular strategy for decomposing your product into functional modules. Hence it is very useful to create microservices.
So, what is a domain as per DDD?
Each problem that you are trying to solve is a domain.
Each domain is subdivided into mutually exclusive bounded contexts. These contexts are nothing but separate areas of that particular problem.
In a microservice pattern, each bounded context correlates to a microservice. DDD patterns help you understand the complexity in the domain. For the domain model for each Bounded Context, you identify and define the
entities, value objects, and aggregates that model your domain.
Depending on the complexity of your software you can choose the DDD principles or perform a simpler approach.
The goal is to achieve a highly cohesive and loosely coupled domain model. For that follow this approach:
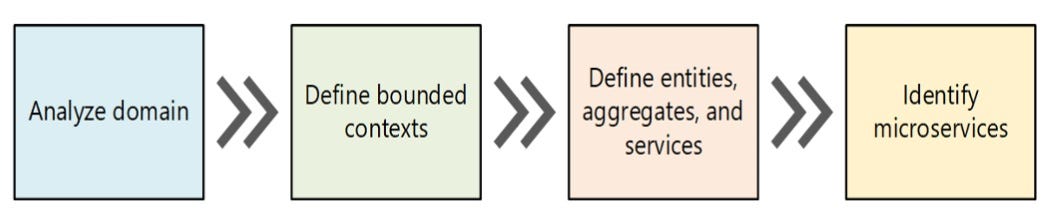
This was a brief intro on the DDD. To learn more about it, I highly recommend reading Eric Evans’s excellent book http://bit.ly/2Eoy17l.
Moving on.
I hope you are holding on with me. 😜
So from here on, I will talk more about practices specific to NodeJS. And what I mean is that microservices and DDD help you benchmark the true potential of NodeJS nevertheless. It’s complete in itself. How? We will see.
Which Design Pattern to use while using NodeJs


Design Patterns are about designing software using certain standards that are known to a number of developers.
There are various design patterns we can use. I would like to introduce and/or recap for developers who already know about a pattern called the Repository Pattern.
This pattern makes it easier to separate the MVC logic while also making it easier to handle model definition and model interaction with the rest of the logic.
It consists of:
- Controller: It only handles the request and response and associated attributes. It will not have any business logic or model definition or model associations too. (folder name: controllers)
- Service: It contains business logic for your microservice. The control passes from controller to a service. It’s a 1:1 relationship between a controller and its service and a 1: many relationships between service and repositories. (folder name: services)
- Repository: It interacts with the models that are part of the model folder. Any query to the database through the model layer will be formed here. It will not have any business logic. (folder name: repositories)
- Model: It contains the model definition, associations, virtual functions (eg. in mongoose)
- Utilities: This will contain helper classes/functions that can be used as services. Eg: a Redis utility that has all the functions required to interact with Redis. (folder name: utilities)
- Test case: This will include unit test cases against controller methods to ensure maximum code coverage. (folder name: spec)
To read more on this, you can refer to this link: http://bit.ly/2TrSyRS
Ok, Tell me about cluster modules
A single instance of Node.js runs in a single thread. To take advantage of multi-core systems, the user will sometimes want to launch a cluster of Node.js processes to handle the load.
The cluster module allows easy creation of child processes that all share server ports.
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
cluster.on('exit', (worker, code, signal) => {
console.log(`worker ${worker.process.pid} died`);
});
} else {
// Workers can share any TCP connection
// In this case it is an HTTP server
http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world\n');
}).listen(8000);
console.log(`Worker ${process.pid} started`);
}
Cluster-module-example.js
Please note that it’s ideal to use one process per container while using Docker containerization for deployment through microservices. Hence, cluster modules aren’t useful when using docker-ization.
How to handle control flow in NodeJS
While using callbacks or promises, the following libraries could be useful:
- Async (https://www.npmjs.com/package/async)
- Vasync( with better tracking of operation) https://www.npmjs.com/package/vasync
- Bluebird ( handle promises eg. Promise.all etc.) https://www.npmjs.com/package/bluebird
And Loops?
- Series loop: executing each step one by one in order
async (items) => {
for (let i = 0; i < items.length; i++) {
const result = await db.get(items[i]);
console.log(result);
}
}
**Series-loop.js **
- Delayed loop: loop with a timeout
const randForTen = async() => {
let results = [];
for (let i = 0; i < 10; i++) {
await timeoutPromise(1000);
results.push(Math.random());
}
return results;
}
Delayed-loop.js
- Parallel loop: collecting all promises in a loop and execute in parallel
async (items) => {
let promises = [];
for (let i = 0; i < items.length; i++) {
promises.push(db.get(items[i]));
}
const results = await Promise.all(promises);
console.log(results);
}
Parallel-loop.js
And what are some useful linting tools?
Linting tools analyze your code statically (without running it). They identify potential bugs or dangerous patterns. Patterns like the use of undeclared variables, or “case” statements inside a switch without a “break” statement.
Enabling strict mode on your codebase with ‘use strict’ can help your code fail fast if the JavaScript parser can identify a leaked global or similar bad behaviour.
Examples of linters are Javascript lint and JS lint.
Ok, how do we handle Logging?
Some commonly used npm packages are:
- Winston (https://www.npmjs.com/package/winston)
- Bunyan (https://www.npmjs.com/package/bunyan)
Possible logging format:
{ "message": "some message", "timestamp": "2013-12-11T08:01:45.000Z",
"version": "1", "host": "cdenza", "clientip": "127.0.0.1", "ident": "-",
"auth": "-", "verb": "GET", "request": "/xampp/status.php", "httpversion":
"1.1", "response": "200"}
Logging-format-example.json
For distributed systems like microservices, you would like to explore distributed tracing using ZipKin etc.
A note on NPM packages : You should use a package only if it solves a problem for you that you can’t solve yourself. Regularly perform npm audits to find critical issues with your npm dependencies.
Handling uncaught exceptions
By default, Node.js handles such exceptions by printing the stack trace to stderr and exiting with code 1, overriding any previously set process.exitCode
Note: Adding a handler for the ‘uncaughtException’ event overrides this default behaviour.
Alternatively, change the process.exitCode in the ‘uncaughtException’ handler which will result in the process exiting with the provided exit code. Otherwise, in the presence of such a handler, the process will exit with 0.
process.exit(0) – successful termination
process.exit(1) – unsuccessful termination
Handling unhandled rejections

Promises are ubiquitous in Node.js code and sometimes chained to a very long list of functions that return promises and so on.
Not using a proper .catch(…) rejection handler will cause an unhandledRejection event to be emitted. If not properly caught and inspected, you may rob yourself of your only chance to detect and possibly fix the problem.
Extra Tip:
console.time() and console.timeEnd()
The console object has time() and timeEnd() methods that help with analyzing the performance of pieces of your code.
console.time("Time this");
for (var i = 0; i < 10000; i++) { // Your stuff here }
console.timeEnd("Time this");
Console-example.js
This is not a solution for production but it can be used when you don’t have better tools.
Thank you very much for your time. Sign Up For My Newsletter
✅30s ad
☞ Node.js for beginners, 10 developed projects, 100% practical
☞ Node.js - From Zero to Web App
☞ Typescript Async/Await in Node JS with testing
☞ Projects in Node.js - Learn by Example
Suggest:
☞ Top 4 Programming Languages to Learn In 2019
☞ Introduction to Functional Programming in Python
☞ Dart Programming Tutorial - Full Course
☞ Ecommerce Furniture App UI Design - Flutter UI - Speed Code
☞ Microservices Tutorial || Build a Complete Vue Python Microservices Application