Node.js process load balance performance: iptables and Nginx

- Node cluster core module having a master process listen on a port and distribute connections to workers
- iptables linux kernel module using prerouting to redirect connections to Node’s child processes listening on multiple ports
- Nginx as a reverse proxy passing connections to Node’s child processes listening on multiple ports
Tests ran on Node 6.0.0 and results measured by:
- Load distribution - how is the load spread across processes
- Total requests and request rate
- Memory used by master and workers
Note: This is not a stress test. I’m doing the same “average” load to compare results against each of the three solutions.
TLDR: Jump to results
Motivation
I’ve been doing multi-machine, multi-core applications using Node since version 0.2.4 in 2010. At that time, for security reasons I used Nginx as a reverse proxy to Node. Later I began using iptables to forward connections to workers and recently I’ve been using Node’s cluster module.
Why compare them? Node cluster module now looks like the obvious choice. Is it? A little bit of history…
In 2012, Node version 0.8 got the addition of the built-in cluster module.
Cluster lets you set up a master process that can handle load to worker processes. The first implementation of the cluster module let the operational system decide how to distribute load. That did not work as expected and later in 2015 Ben confirmed the problem:
“Now, we get to the part where theory meets messy reality because it slowly became clear that the operating system’s idea of ‘best’ is not always aligned with that of the programmer. In particular, it was observed that sometimes — particularly on Linux and Solaris — most connections ended up in just two or three processes.” — Ben Noordhuis
To fix that Node v0.12 got a new implementation using a round-robin algorithm to distribute the load between workers in a better way. This is the default approach Node uses since then including Node v6.0.0:
“… the master process listens on a port, accepts new connections and distributes them across the workers in a round-robin fashion” — Node 6.0.0 cluster module documentation
This is what I want. Load evenly distributed between workers NOT done by the SO. But if we keep reading the cluster module doc, we’ll get to this point:
“The [OS distribution] approach should, in theory, give the best performance.
In practice however, distribution tends to be very unbalanced due to operating system scheduler vagaries. Loads have been observed where over 70% of all connections ended up in just two processes, out of a total of eight” — Node 6.0.0 cluster module documentation
Same thing Ben Noordhuis said on his quote above. The OS distribution approach is essentially broken. We already knew that. But there is another piece of information: “the [OS distribution] approach should, in theory, give the best performance”. So, the approach that gives the best performance is the one that I’m NOT using.
It begs the question: how much performance do we lose by using the default cluster approach compared to solutions that handle the load directly to workers? That’s what I wanted to find out.
Setup
This test compare number of requests and memory usage of Node when running with Cluster module, iptables and Nginx as process load balancers.
Lets also compare how well these solutions distribute connections between workers/child processes.
Hardware & Software
- Machine receiving the load is physical hardware with 8 CPU cores / 8GB RAM using Node.js v6.0.0. — cpuinfo
- Machine generating the load has the same specs as above and is running Siege with this command and config
- sysctl, ulimits and friends configured to do not be a bottleneck for the tests. The most important configs are these
- iptables with nat and prerouting configuration to redirect from port 80 to Node.js workers on ports [8080–8087]
- Nginx configured with 1 worker per core and upstream proxy pass to Node.js workers on ports [8080–8087]
Source code
Node using core cluster module test case. Code simplified without require() and logs. Full code here.
class Cluster {
constructor () {
if (cluster.isMaster) {
this.fork()
}
else {
new Worker()
}
}
fork () {
let cpus = os.cpus().length
for (let i = 0; i < cpus; i++) {
cluster.fork({id: i})
}
}
}
new Cluster()
cluster.js
let type = 'cluster'
let hit = 0, id
class Worker {
constructor () {
id = Number(process.env.id)
this.webserver()
}
webserver () {
let server = http.createServer((req, res) => {
res.writeHead(200)
res.end('ok')
}).listen(80, () => {
console.log('Worker', id, 'listening on port', server.address().port)
})
}
}
module.exports = Worker
cluster-worker.js
Node using child_processes behind iptables test case. Code simplified without require() and logs. Full code here.
let type = 'iptables'
class Iptables {
constructor () {
this.fork()
}
fork (id) {
let cpus = os.cpus().length
for (let i = 0; i < cpus; i++) {
cp.fork('./'+ type +'-worker', {env: {id: i}})
}
}
}
new Iptables()
iptables.js
let type = 'iptables'
let hit = 0, id
class Worker {
constructor () {
id = Number(process.env.id)
this.webserver()
}
webserver () {
let server = http.createServer((req, res) => {
res.writeHead(200)
res.end('ok')
}).listen(8080 + id, () => {
console.log('Worker', id, 'listening on port', server.address().port)
})
}
}
new Worker()
iptables-worker.js
Node using child_processes behind Nginx test case. Code simplified without require() and logs. Full code here.
let type = 'nginx'
class Nginx {
constructor () {
this.fork()
}
fork (id) {
let cpus = os.cpus().length
for (let i = 0; i < cpus; i++) {
cp.fork('./'+ type +'-worker', {env: {id: i}})
}
}
}
new Nginx()
nginx.js
let type = 'nginx'
let hit = 0, id
class Worker {
constructor () {
id = Number(process.env.id)
this.webserver()
}
webserver () {
let server = http.createServer((req, res) => {
res.writeHead(200)
res.end('ok')
}).listen(8080 + id, () => {
console.log('Worker', id, 'listening on port', server.address().port)
})
}
}
new Worker()
nginx-worker.js
Results
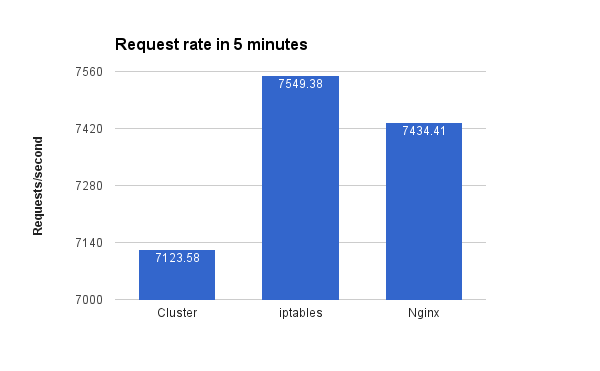
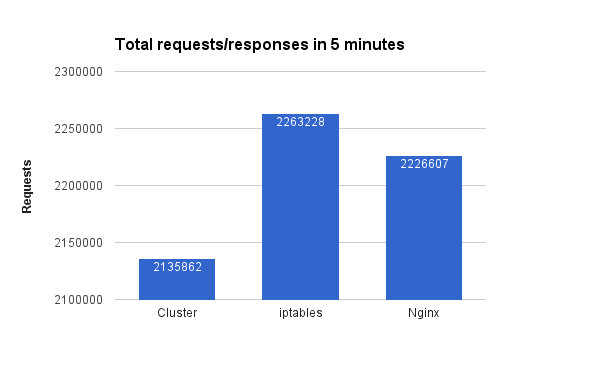
Total requests and request rate
Shows how many responses to requests these solutions were able to give in 5 minutes. Take a closer look to the numbers, not only the graph bars. Node behind iptables was able to respond to approx 5.8% more requests than cluster module and 1.6% more than Nginx.
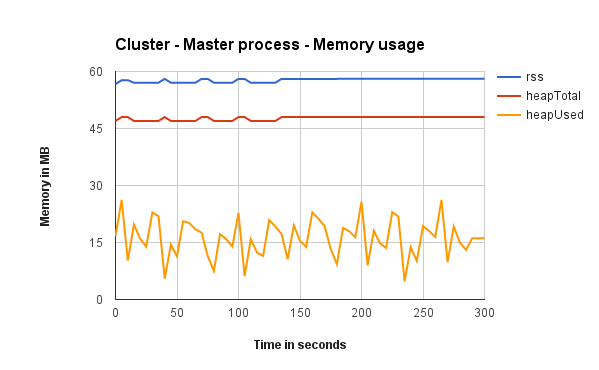
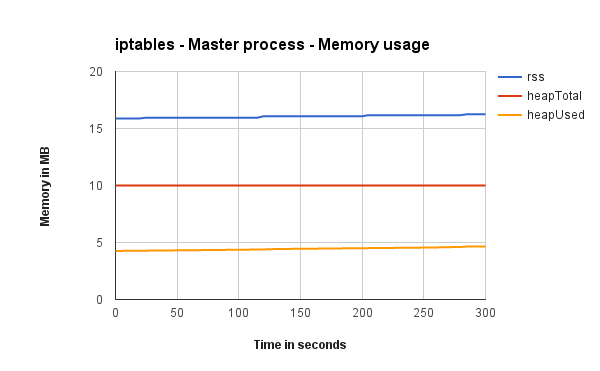
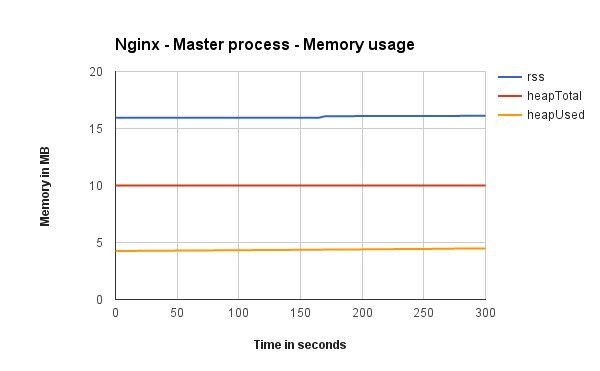
Master process memory usage
These show how much memory Node’s master process is using when running with Cluster, iptables and Nginx (one graph each).
As expected while using the cluster module the master process is responsible for handling the load to workers. That’s not free. Master process of cluster uses triple the amount of memory of the master process behind Nginx and iptables (which are doing almost nothing).
Worker process memory usage
Shows how much memory Node’s worker 1 (out of 8) process is using when running with Cluster, iptables and Nginx (one graph each). It does not matter if its from Cluster, iptables or Nginx, all graphs show that workers use almost the same amount of memory.
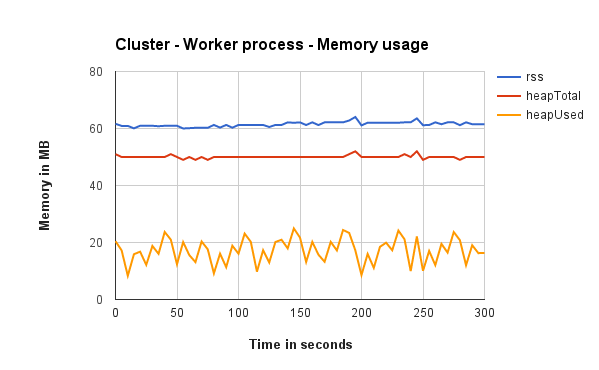
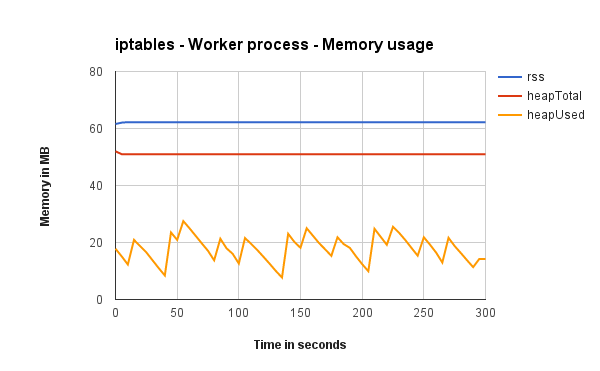
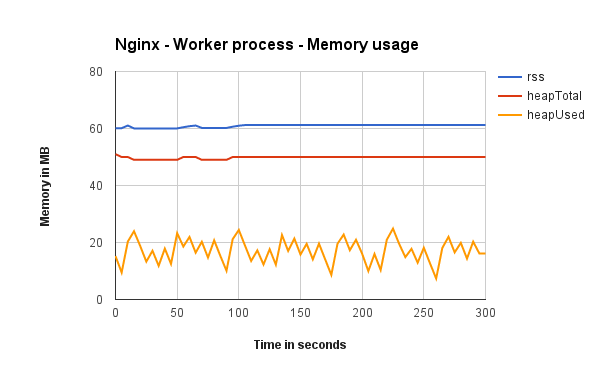
Request distribution between processes
This is how each solution decided to spread requests to their workers. Pay attention to the actual numbers as the bars may look far apart but the numbers not so much. Also, iptables does a perfect round-robin distribution.
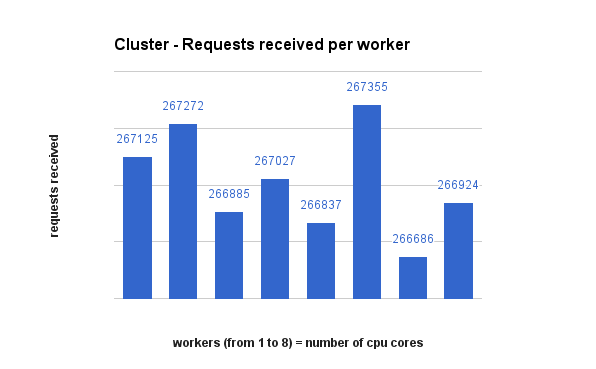
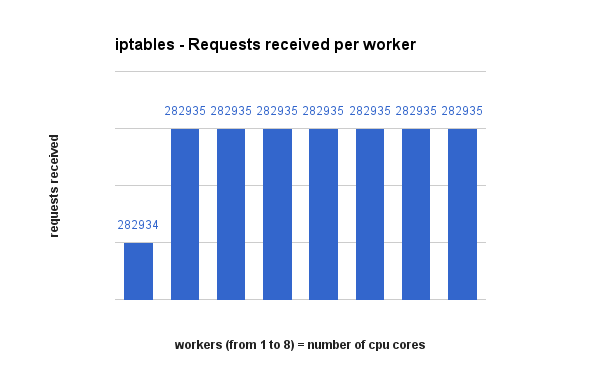
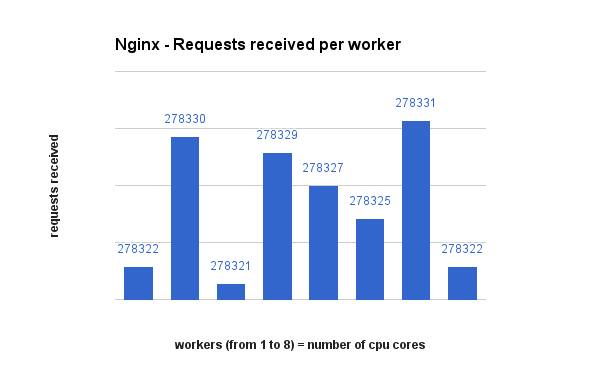
Raw data, csv and final result files can be found here
Conclusion / opinion
Nginx, being a full fledged webserver, did very well. One thing that is not accounted for is that Nginx will usually double the number of file descriptors (sockets). One for the client connection and another for the proxied server (Node). This will increase memory usage. Nginx will also need memory for itself to run. But if you need a world class, secure and full-featured webserver put Nginx in front of it.
{kind=link}
Node cluster is simple to implement and configure, things are kept inside Node’s realm without depending on other software. Just remember your master process will work almost as much as your worker processes and with a little less request rate then the other solutions.
Use iptables when you need to squeeze as much performance as possible from your process load balancer and application. As a kernel module, it is not that easy to get memory usage from iptables. A small downside is having to configure port forwarding manually according to the number of cores on your machine and remember to reconfigure if you deploy on machines with different number of cores.
Recommended Courses:
Introduction to NodeJS - Learn and Understand JavaScript
☞ http://bit.ly/2Kqs9ff
Webpack 2: The Complete Developer’s Guide
☞ http://bit.ly/2M0t1bJ
Angular 2 and NodeJS - The Practical Guide to MEAN Stack 2.0
☞ http://bit.ly/2LZZK0O
The Full Stack Web Development
☞ http://bit.ly/2OiROZX
Suggest:
☞ JavaScript Programming Tutorial Full Course for Beginners
☞ Learn JavaScript - Become a Zero to Hero
☞ Javascript Project Tutorial: Budget App
☞ E-Commerce JavaScript Tutorial - Shopping Cart from Scratch